Extraterm
Tested Software version 0.81.4 on Linux. The homepage URL of this terminal is https://extraterm.org/. Full results available at ucs-detect repository path data/extraterm.yaml.
Score Breakdown
Detailed breakdown of how scores are calculated for Extraterm:
# |
Score Type |
Raw Score |
Final Scaled Score |
|---|---|---|---|
1 |
99.42% |
99.2% |
|
2 |
100.00% |
100.0% |
|
3 |
0.00% |
0.0% |
|
4 |
69.57% |
69.5% |
|
5 |
100.00% |
100.0% |
|
6 |
0.00% |
(excluded) |
|
7 |
0.00% |
0.0% |
|
8 |
100.00% |
100.0% |
|
9 |
98.85% |
98.9% |
|
10 |
3.12% |
3.3% |
|
11 |
0% |
0.0% |
|
12 |
20.5% |
20.5% |
Score Comparison Plot:
The following plot shows how this terminal’s scores compare to all other terminals tested.
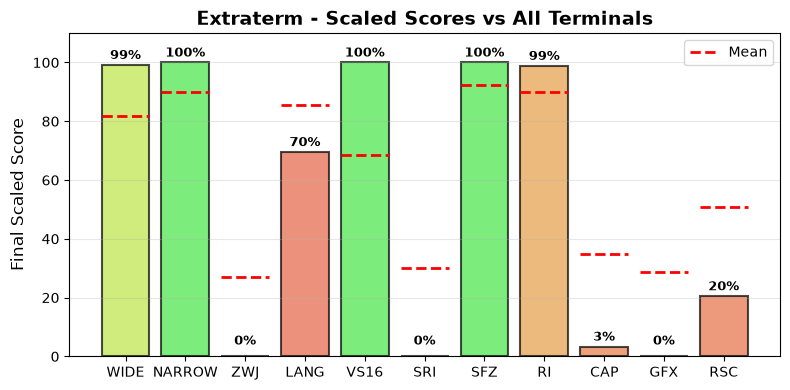
Scaled scores comparison across all metrics (normalized 0-100%)
Final Scaled Score Calculation:
Raw Final Score: 53.23% (weighted average: WIDE + NARROW + ZWJ + LANG + VS16 + 0.33 * SRI + 0.33 * SFZ + RI + CAP + 0.5 * GFX + 0.5 * RSC) the categorized ‘average’ absolute support level of this terminal.
Note
RSC (Resources) is a composite CPU, memory, and runtime score. RSC is weighted at 0.5 (half as powerful as other metrics). FEAT (Features) is the fraction of notable features supported. GFX (Graphics) scores 100% for modern protocols (iTerm2, Kitty), 50% for legacy only (Sixel, ReGIS), 0% for none.
Final Scaled Score: 31.6% (normalized across all terminals tested). Final Scaled scores are normalized (0-100%) relative to all terminals tested
WIDE Score Details:
Wide character support calculation:
Total successful codepoints: 43337
Total codepoints tested: 43592
Formula: 43337 / 43592
Result: 99.42%
NARROW Score Details:
Narrow character support calculation:
Total successful codepoints: 36254
Total codepoints tested: 36254
Formula: 36254 / 36254
Result: 100.00%
ZWJ Score Details:
Emoji ZWJ (Zero-Width Joiner) support calculation:
Total successful sequences: 0
Total sequences tested: 1445
Formula: 0 / 1445
Result: 0.00%
VS16 Score Details:
Variation Selector-16 support calculation:
Errors: 0 of 426 codepoints tested
Success rate: 100.0%
Formula: 100.0 / 100
Result: 100.00%
VS15 Score Details (excluded from final score):
Variation Selector-15 support calculation:
Errors: 158 of 158 codepoints tested
Success rate: 0.0%
Formula: 0.0 / 100
Result: 0.00%
SRI Score Details:
Standalone Regional Indicator support calculation:
Total successful codepoints: 0
Total codepoints tested: 26
Formula: 0 / 26
Result: 0.00%
SFZ Score Details:
Standalone Fitzpatrick skin tone modifier support calculation:
Total successful codepoints: 5
Total codepoints tested: 5
Formula: 5 / 5
Result: 100.00%
RI Score Details:
Regional Indicator flag sequence support calculation:
Total successful sequences: 259
Total sequences tested: 262
Formula: 259 / 262
Result: 98.85%
Features Score Details:
Notable terminal features (0.5 / 16):
Kitty Keyboard: no
XTGETTCAP: no
OSC 52 Clipboard: no
Truecolor Detection: partial
Raw score: 3.12%
Graphics Score Details:
Graphics protocol support (0%):
Sixel: no
ReGIS: no
iTerm2: no
Kitty: no
Scoring: 100% for modern (iTerm2/Kitty), 50% for legacy only (Sixel/ReGIS), 0% for none
Resource Score Details:
Duration: 307.7s
Mean CPU: 30.9%
Mean RSS: 351.6 MB
Resources Score: 20/100
Note: log-scale composite cost = log(CPU+1) + log(RSS+1) + log(time+1)
Scaled result: 20.5%
LANG Score Details (Geometric Mean):
Geometric mean calculation:
Formula: (p₁ × p₂ × … × pₙ)^(1/n) where n = 118 languages
About geometric mean
Result: 69.57%
Wide character support
Wide character support of Extraterm is 99.4% (255 errors of 43592 codepoints tested).
Sequence of a WIDE character, from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\U0001d32a’ |
So |
2 |
TETRAGRAM FOR PURITY |
Total codepoints: 1
Shell test using printf(1),
'|'should align in output:$ printf "\xf0\x9d\x8c\xaa|\\n12|\\n" 𝌪| 12|
See Line 42277 of ucs_wide.txt for this sequence in the example file.
Screenshot:
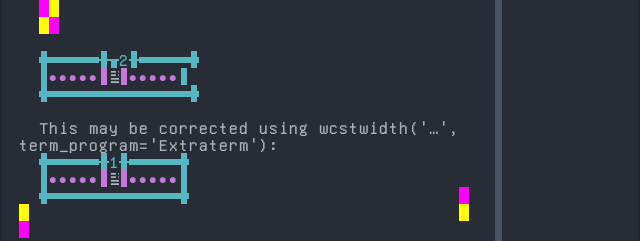
python wcwidth.wcswidth() measures width 2, while Extraterm measures width 1.
Narrow character support
Narrow character support of Extraterm is 100.0% (0 errors of 36254 codepoints tested).
Emoji ZWJ support
Compatibility of Extraterm with the Unicode Emoji ZWJ sequence table is 0.0% (1445 errors of 1445 sequences tested).
Sequence of an Emoji ZWJ Sequence, from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\U0001f3c3’ |
So |
2 |
RUNNER |
|
2 |
‘\U0001f3ff’ |
Sk |
2 |
EMOJI MODIFIER FITZPATRICK TYPE-6 |
|
3 |
‘\u200d’ |
Cf |
0 |
ZERO WIDTH JOINER |
|
4 |
‘\u2640’ |
So |
1 |
FEMALE SIGN |
|
5 |
‘\ufe0f’ |
Mn |
0 |
VARIATION SELECTOR-16 |
Total codepoints: 5
Shell test using printf(1),
'|'should align in output:$ printf "\xf0\x9f\x8f\x83\xf0\x9f\x8f\xbf\xe2\x80\x8d\xe2\x99\x80\xef\xb8\x8f|\\n12|\\n" 🏃🏿♀️| 12|
Screenshot:
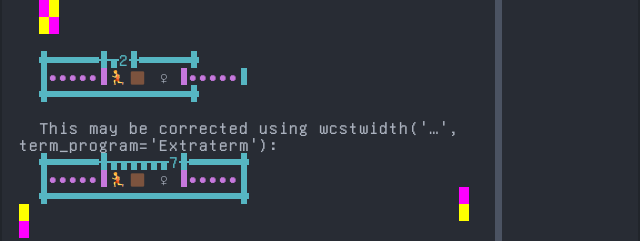
python wcwidth.wcswidth() measures width 2, while Extraterm measures width 7.
Variation Selector-16 support
Emoji VS-16 results for Extraterm is 0 errors out of 426 total codepoints tested, 100.0% success. All codepoint combinations with Variation Selector-16 tested were successful.
Variation Selector-15 support
Emoji VS-15 results for Extraterm is 158 errors out of 158 total codepoints tested, 0.0% success. Sequence of a WIDE Emoji made NARROW by Variation Selector-15, from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\U0001f3ae’ |
So |
2 |
VIDEO GAME |
|
2 |
‘\ufe0e’ |
Mn |
0 |
VARIATION SELECTOR-15 |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xf0\x9f\x8e\xae\xef\xb8\x8e|\\n1|\\n" 🎮︎| 1|
Screenshot:
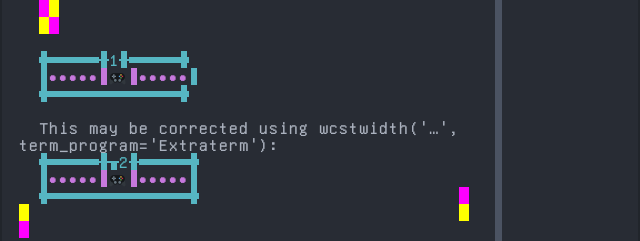
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
Standalone Regional Indicator support
Standalone Regional Indicator support of Extraterm is 0.0% (26 errors of 26 codepoints tested).
Sequence of a standalone Regional Indicator, from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\U0001f1f3’ |
So |
2 |
REGIONAL INDICATOR SYMBOL LETTER N |
Total codepoints: 1
Shell test using printf(1),
'|'should align in output:$ printf "\xf0\x9f\x87\xb3|\\n12|\\n" 🇳| 12|
Screenshot:
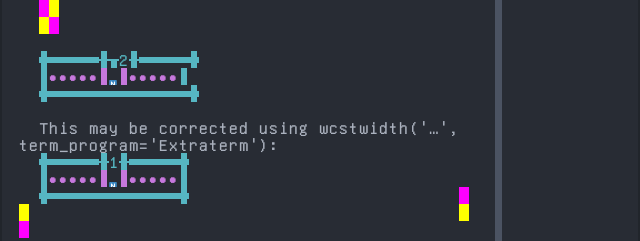
python wcwidth.wcswidth() measures width 2, while Extraterm measures width 1.
Standalone Fitzpatrick modifier support
Standalone Fitzpatrick skin tone modifier support of Extraterm is 100.0% (0 errors of 5 codepoints tested).
Regional Indicator flag sequence support
Regional Indicator flag sequence support of Extraterm is 98.9% (3 errors of 262 sequences tested).
Sequence of a Regional Indicator flag sequence, from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\U0001f3f4’ |
So |
2 |
WAVING BLACK FLAG |
|
2 |
‘\U000e0067’ |
Cf |
0 |
TAG LATIN SMALL LETTER G |
|
3 |
‘\U000e0062’ |
Cf |
0 |
TAG LATIN SMALL LETTER B |
|
4 |
‘\U000e0073’ |
Cf |
0 |
TAG LATIN SMALL LETTER S |
|
5 |
‘\U000e0063’ |
Cf |
0 |
TAG LATIN SMALL LETTER C |
|
6 |
‘\U000e0074’ |
Cf |
0 |
TAG LATIN SMALL LETTER T |
|
7 |
‘\U000e007f’ |
Cf |
0 |
CANCEL TAG |
Total codepoints: 7
Shell test using printf(1),
'|'should align in output:$ printf "\xf0\x9f\x8f\xb4\xf3\xa0\x81\xa7\xf3\xa0\x81\xa2\xf3\xa0\x81\xb3\xf3\xa0\x81\xa3\xf3\xa0\x81\xb4\xf3\xa0\x81\xbf|\\n12|\\n" 🏴| 12|
Screenshot:
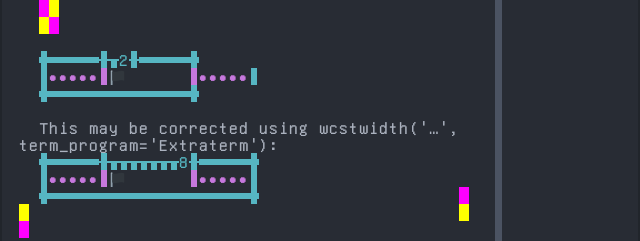
python wcwidth.wcswidth() measures width 2, while Extraterm measures width 8.
Graphics Protocol Support
Extraterm does not report support for any graphics protocols.
Detection Methods:
Sixel and ReGIS: Detected via the Device Attributes (DA1) query
CSI c(\x1b[c). Extension code4indicates Sixel support,3ReGIS.Kitty graphics: Detected by sending a Kitty graphics query and checking for an
OKresponse.iTerm2 inline images: Detected via the iTerm2 capabilities query
OSC 1337 ; Capabilities.
Device Attributes Response:
Language Support
The following 24 languages were tested with 100% success:
(Jinan), (Yeonbyeon), Chinese, Gan, Chinese, Hakka, Chinese, Jinyu, Chinese, Mandarin (Beijing), Chinese, Mandarin (Guiyang), Chinese, Mandarin (Harbin), Chinese, Mandarin (Nanjing), Chinese, Mandarin (Simplified), Chinese, Mandarin (Tianjin), Chinese, Mandarin (Traditional), Chinese, Min Nan, Chinese, Wu, Chinese, Xiang, Chinese, Yue, Colorado, Japanese, Japanese (Osaka), Japanese (Tokyo), Korean, Mongolian, Halh (Mongolian), Nuosu, Vietnamese (Han nom).
The following 94 languages are not fully supported:
lang |
n_errors |
n_total |
pct_success |
|---|---|---|---|
209 |
226 |
7.5% |
|
337 |
396 |
14.9% |
|
449 |
530 |
15.3% |
|
179 |
214 |
16.4% |
|
160 |
200 |
20.0% |
|
217 |
277 |
21.7% |
|
258 |
332 |
22.3% |
|
200 |
267 |
25.1% |
|
286 |
384 |
25.5% |
|
186 |
252 |
26.2% |
|
193 |
262 |
26.3% |
|
132 |
181 |
27.1% |
|
354 |
493 |
28.2% |
|
192 |
268 |
28.4% |
|
294 |
443 |
33.6% |
|
120 |
189 |
36.5% |
|
247 |
390 |
36.7% |
|
246 |
391 |
37.1% |
|
224 |
357 |
37.3% |
|
218 |
352 |
38.1% |
|
224 |
385 |
41.8% |
|
479 |
845 |
43.3% |
|
191 |
343 |
44.3% |
|
165 |
302 |
45.4% |
|
171 |
314 |
45.5% |
|
167 |
313 |
46.6% |
|
57 |
117 |
51.3% |
|
16 |
34 |
52.9% |
|
28 |
70 |
60.0% |
|
99 |
258 |
61.6% |
|
104 |
287 |
63.8% |
|
23 |
82 |
72.0% |
|
79 |
293 |
73.0% |
|
19 |
71 |
73.2% |
|
24 |
93 |
74.2% |
|
25 |
110 |
77.3% |
|
17 |
75 |
77.3% |
|
18 |
88 |
79.5% |
|
10 |
49 |
79.6% |
|
8 |
42 |
81.0% |
|
10 |
58 |
82.8% |
|
13 |
77 |
83.1% |
|
12 |
75 |
84.0% |
|
14 |
90 |
84.4% |
|
10 |
67 |
85.1% |
|
26 |
175 |
85.1% |
|
26 |
175 |
85.1% |
|
10 |
68 |
85.3% |
|
11 |
78 |
85.9% |
|
8 |
60 |
86.7% |
|
8 |
61 |
86.9% |
|
7 |
54 |
87.0% |
|
8 |
62 |
87.1% |
|
9 |
70 |
87.1% |
|
6 |
48 |
87.5% |
|
7 |
62 |
88.7% |
|
6 |
54 |
88.9% |
|
8 |
73 |
89.0% |
|
7 |
67 |
89.6% |
|
5 |
53 |
90.6% |
|
6 |
64 |
90.6% |
|
6 |
65 |
90.8% |
|
6 |
65 |
90.8% |
|
5 |
60 |
91.7% |
|
4 |
53 |
92.5% |
|
5 |
72 |
93.1% |
|
4 |
58 |
93.1% |
|
4 |
59 |
93.2% |
|
4 |
62 |
93.5% |
|
5 |
79 |
93.7% |
|
4 |
65 |
93.8% |
|
4 |
66 |
93.9% |
|
4 |
67 |
94.0% |
|
5 |
87 |
94.3% |
|
3 |
56 |
94.6% |
|
3 |
57 |
94.7% |
|
3 |
62 |
95.2% |
|
3 |
63 |
95.2% |
|
4 |
88 |
95.5% |
|
3 |
74 |
95.9% |
|
3 |
79 |
96.2% |
|
2 |
55 |
96.4% |
|
3 |
85 |
96.5% |
|
2 |
59 |
96.6% |
|
2 |
60 |
96.7% |
|
2 |
62 |
96.8% |
|
2 |
64 |
96.9% |
|
2 |
64 |
96.9% |
|
2 |
73 |
97.3% |
|
2 |
84 |
97.6% |
|
1 |
53 |
98.1% |
|
1 |
58 |
98.3% |
|
1 |
59 |
98.3% |
|
1 |
63 |
98.4% |
Maldivian
Sequence of language Maldivian from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0780’ |
Lo |
1 |
THAANA LETTER HAA |
|
2 |
‘\u07a6’ |
Mn |
0 |
THAANA ABAFILI |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xde\x80\xde\xa6|\\n1|\\n" ހަ| 1|
Screenshot:
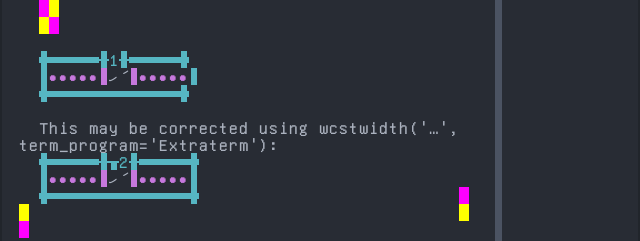
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
Khün
Sequence of language Khün from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u1a20’ |
Lo |
1 |
TAI THAM LETTER HIGH KA |
|
2 |
‘\u1a60’ |
Mn |
0 |
TAI THAM SIGN SAKOT |
|
3 |
‘\u1a20’ |
Lo |
1 |
TAI THAM LETTER HIGH KA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe1\xa8\xa0\xe1\xa9\xa0\xe1\xa8\xa0|\\n12|\\n" ᨠ᩠ᨠ| 12|
Screenshot:

python wcwidth.wcswidth() measures width 2, while Extraterm measures width 3.
Javanese (Javanese)
Sequence of language Javanese (Javanese) from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\ua98f’ |
Lo |
1 |
JAVANESE LETTER KA |
|
2 |
‘\ua9ba’ |
Mc |
0 |
JAVANESE VOWEL SIGN TALING |
|
3 |
‘\ua9b4’ |
Mc |
0 |
JAVANESE VOWEL SIGN TARUNG |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xea\xa6\x8f\xea\xa6\xba\xea\xa6\xb4|\\n12|\\n" ꦏꦺꦴ| 12|
Screenshot:

python wcwidth.wcswidth() measures width 2, while Extraterm measures width 3.
Tibetan, Central
Sequence of language Tibetan, Central from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0f40’ |
Lo |
1 |
TIBETAN LETTER KA |
|
2 |
‘\u0f74’ |
Mn |
0 |
TIBETAN VOWEL SIGN U |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xbd\x80\xe0\xbd\xb4|\\n1|\\n" ཀུ| 1|
Screenshot:
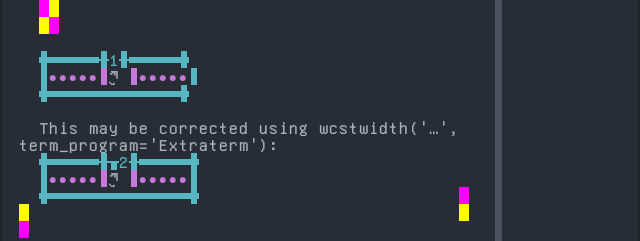
Dzongkha
Sequence of language Dzongkha from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0f40’ |
Lo |
1 |
TIBETAN LETTER KA |
|
2 |
‘\u0f74’ |
Mn |
0 |
TIBETAN VOWEL SIGN U |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xbd\x80\xe0\xbd\xb4|\\n1|\\n" ཀུ| 1|
Screenshot:
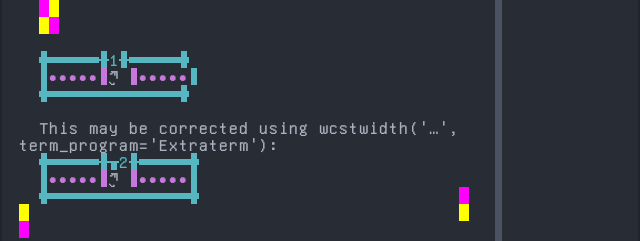
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
Lao
Sequence of language Lao from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0e81’ |
Lo |
1 |
LAO LETTER KO |
|
2 |
‘\u0eb1’ |
Mn |
0 |
LAO VOWEL SIGN MAI KAN |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xba\x81\xe0\xba\xb1|\\n1|\\n" ກັ| 1|
Screenshot:
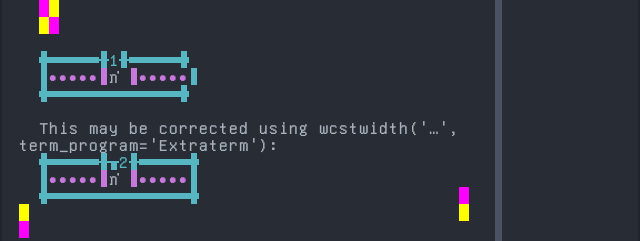
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
Mon
Sequence of language Mon from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u1000’ |
Lo |
1 |
MYANMAR LETTER KA |
|
2 |
‘\u1039’ |
Mn |
0 |
MYANMAR SIGN VIRAMA |
|
3 |
‘\u1001’ |
Lo |
1 |
MYANMAR LETTER KHA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe1\x80\x80\xe1\x80\xb9\xe1\x80\x81|\\n12|\\n" က္ခ| 12|
Screenshot:

Chakma
Sequence of language Chakma from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\U00011103’ |
Lo |
1 |
CHAKMA LETTER AA |
|
2 |
‘\U0001112c’ |
Mc |
0 |
CHAKMA VOWEL SIGN E |
|
3 |
‘\U0001112d’ |
Mn |
0 |
CHAKMA VOWEL SIGN AI |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xf0\x91\x84\x83\xf0\x91\x84\xac\xf0\x91\x84\xad|\\n12|\\n" 𑄃𑄬𑄭| 12|
Screenshot:
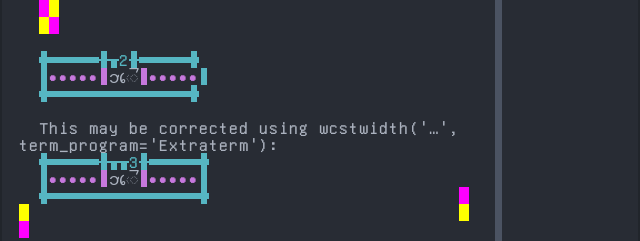
python wcwidth.wcswidth() measures width 2, while Extraterm measures width 3.
Telugu
Sequence of language Telugu from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0c15’ |
Lo |
1 |
TELUGU LETTER KA |
|
2 |
‘\u0c3e’ |
Mn |
0 |
TELUGU VOWEL SIGN AA |
|
3 |
‘\u0c02’ |
Mc |
0 |
TELUGU SIGN ANUSVARA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xb0\x95\xe0\xb0\xbe\xe0\xb0\x82|\\n12|\\n" కాం| 12|
Screenshot:

python wcwidth.wcswidth() measures width 2, while Extraterm measures width 3.
Thai (2)
Sequence of language Thai (2) from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0e22’ |
Lo |
1 |
THAI CHARACTER YO YAK |
|
2 |
‘\u0e48’ |
Mn |
0 |
THAI CHARACTER MAI EK |
|
3 |
‘\u0e33’ |
Lo |
1 |
THAI CHARACTER SARA AM |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xb8\xa2\xe0\xb9\x88\xe0\xb8\xb3|\\n12|\\n" ย่ำ| 12|
Screenshot:

python wcwidth.wcswidth() measures width 2, while Extraterm measures width 3.
Thai
Sequence of language Thai from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0e15’ |
Lo |
1 |
THAI CHARACTER TO TAO |
|
2 |
‘\u0e48’ |
Mn |
0 |
THAI CHARACTER MAI EK |
|
3 |
‘\u0e33’ |
Lo |
1 |
THAI CHARACTER SARA AM |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xb8\x95\xe0\xb9\x88\xe0\xb8\xb3|\\n12|\\n" ต่ำ| 12|
Screenshot:

python wcwidth.wcswidth() measures width 2, while Extraterm measures width 3.
Shan
Sequence of language Shan from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u1004’ |
Lo |
1 |
MYANMAR LETTER NGA |
|
2 |
‘\u103a’ |
Mn |
0 |
MYANMAR SIGN ASAT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe1\x80\x84\xe1\x80\xba|\\n1|\\n" င်| 1|
Screenshot:
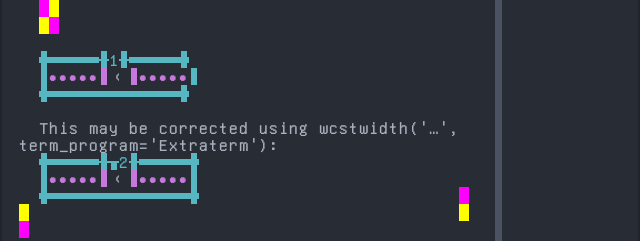
Sanskrit
Sequence of language Sanskrit from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
|
2 |
‘\u093e’ |
Mc |
0 |
DEVANAGARI VOWEL SIGN AA |
|
3 |
‘\u0902’ |
Mn |
0 |
DEVANAGARI SIGN ANUSVARA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa4\x95\xe0\xa4\xbe\xe0\xa4\x82|\\n12|\\n" कां| 12|
Screenshot:

Burmese
Sequence of language Burmese from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u1000’ |
Lo |
1 |
MYANMAR LETTER KA |
|
2 |
‘\u1039’ |
Mn |
0 |
MYANMAR SIGN VIRAMA |
|
3 |
‘\u1001’ |
Lo |
1 |
MYANMAR LETTER KHA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe1\x80\x80\xe1\x80\xb9\xe1\x80\x81|\\n12|\\n" က္ခ| 12|
Screenshot:

python wcwidth.wcswidth() measures width 2, while Extraterm measures width 3.
Khmer, Central
Sequence of language Khmer, Central from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u1780’ |
Lo |
1 |
KHMER LETTER KA |
|
2 |
‘\u17d2’ |
Mn |
0 |
KHMER SIGN COENG |
|
3 |
‘\u1781’ |
Lo |
1 |
KHMER LETTER KHA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe1\x9e\x80\xe1\x9f\x92\xe1\x9e\x81|\\n12|\\n" ក្ខ| 12|
Screenshot:
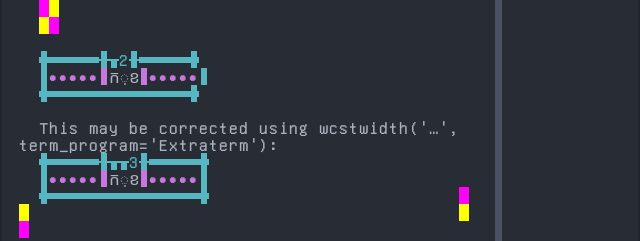
python wcwidth.wcswidth() measures width 2, while Extraterm measures width 3.
Tai Dam
Sequence of language Tai Dam from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\uaa80’ |
Lo |
1 |
TAI VIET LETTER LOW KO |
|
2 |
‘\uaab0’ |
Mn |
0 |
TAI VIET MAI KANG |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xea\xaa\x80\xea\xaa\xb0|\\n1|\\n" ꪀꪰ| 1|
Screenshot:
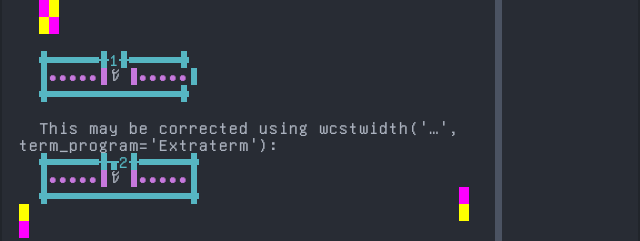
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
Hindi
Sequence of language Hindi from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
|
2 |
‘\u094d’ |
Mn |
0 |
DEVANAGARI SIGN VIRAMA |
|
3 |
‘\u0924’ |
Lo |
1 |
DEVANAGARI LETTER TA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa4\x95\xe0\xa5\x8d\xe0\xa4\xa4|\\n12|\\n" क्त| 12|
Screenshot:
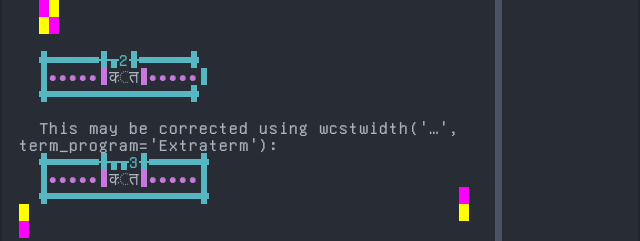
Marathi
Sequence of language Marathi from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
|
2 |
‘\u093e’ |
Mc |
0 |
DEVANAGARI VOWEL SIGN AA |
|
3 |
‘\u0902’ |
Mn |
0 |
DEVANAGARI SIGN ANUSVARA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa4\x95\xe0\xa4\xbe\xe0\xa4\x82|\\n12|\\n" कां| 12|
Screenshot:

Maithili
Sequence of language Maithili from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
|
2 |
‘\u093e’ |
Mc |
0 |
DEVANAGARI VOWEL SIGN AA |
|
3 |
‘\u0902’ |
Mn |
0 |
DEVANAGARI SIGN ANUSVARA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa4\x95\xe0\xa4\xbe\xe0\xa4\x82|\\n12|\\n" कां| 12|
Screenshot:

Nepali
Sequence of language Nepali from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
|
2 |
‘\u093e’ |
Mc |
0 |
DEVANAGARI VOWEL SIGN AA |
|
3 |
‘\u0902’ |
Mn |
0 |
DEVANAGARI SIGN ANUSVARA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa4\x95\xe0\xa4\xbe\xe0\xa4\x82|\\n12|\\n" कां| 12|
Screenshot:

Bengali
Sequence of language Bengali from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0995’ |
Lo |
1 |
BENGALI LETTER KA |
|
2 |
‘\u09be’ |
Mc |
0 |
BENGALI VOWEL SIGN AA |
|
3 |
‘\u200c’ |
Cf |
0 |
ZERO WIDTH NON-JOINER |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa6\x95\xe0\xa6\xbe\xe2\x80\x8c|\\n12|\\n" কা| 12|
Screenshot:

python wcwidth.wcswidth() measures width 2, while Extraterm measures width 3.
Malayalam
Sequence of language Malayalam from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0d15’ |
Lo |
1 |
MALAYALAM LETTER KA |
|
2 |
‘\u0d4d’ |
Mn |
0 |
MALAYALAM SIGN VIRAMA |
|
3 |
‘\u0d15’ |
Lo |
1 |
MALAYALAM LETTER KA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xb4\x95\xe0\xb5\x8d\xe0\xb4\x95|\\n12|\\n" ക്ക| 12|
Screenshot:

python wcwidth.wcswidth() measures width 2, while Extraterm measures width 3.
Gujarati
Sequence of language Gujarati from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0a95’ |
Lo |
1 |
GUJARATI LETTER KA |
|
2 |
‘\u0abe’ |
Mc |
0 |
GUJARATI VOWEL SIGN AA |
|
3 |
‘\u0a82’ |
Mn |
0 |
GUJARATI SIGN ANUSVARA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xaa\x95\xe0\xaa\xbe\xe0\xaa\x82|\\n12|\\n" કાં| 12|
Screenshot:

python wcwidth.wcswidth() measures width 2, while Extraterm measures width 3.
Panjabi, Eastern
Sequence of language Panjabi, Eastern from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0a15’ |
Lo |
1 |
GURMUKHI LETTER KA |
|
2 |
‘\u0a3e’ |
Mc |
0 |
GURMUKHI VOWEL SIGN AA |
|
3 |
‘\u0a02’ |
Mn |
0 |
GURMUKHI SIGN BINDI |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa8\x95\xe0\xa8\xbe\xe0\xa8\x82|\\n12|\\n" ਕਾਂ| 12|
Screenshot:

python wcwidth.wcswidth() measures width 2, while Extraterm measures width 3.
Magahi
Sequence of language Magahi from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
|
2 |
‘\u094d’ |
Mn |
0 |
DEVANAGARI SIGN VIRAMA |
|
3 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa4\x95\xe0\xa5\x8d\xe0\xa4\x95|\\n12|\\n" क्क| 12|
Screenshot:

Bhojpuri
Sequence of language Bhojpuri from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
|
2 |
‘\u094d’ |
Mn |
0 |
DEVANAGARI SIGN VIRAMA |
|
3 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa4\x95\xe0\xa5\x8d\xe0\xa4\x95|\\n12|\\n" क्क| 12|
Screenshot:

python wcwidth.wcswidth() measures width 2, while Extraterm measures width 3.
Vietnamese
Sequence of language Vietnamese from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘a’ |
Ll |
1 |
LATIN SMALL LETTER A |
|
2 |
‘\u0300’ |
Mn |
0 |
COMBINING GRAVE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "a\xcc\x80|\\n1|\\n" à| 1|
Screenshot:
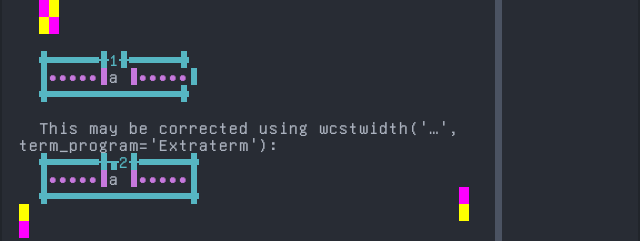
Tagalog (Tagalog)
Sequence of language Tagalog (Tagalog) from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u1704’ |
Lo |
1 |
TAGALOG LETTER GA |
|
2 |
‘\u1714’ |
Mn |
0 |
TAGALOG SIGN VIRAMA |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe1\x9c\x84\xe1\x9c\x94|\\n1|\\n" ᜄ᜔| 1|
Screenshot:
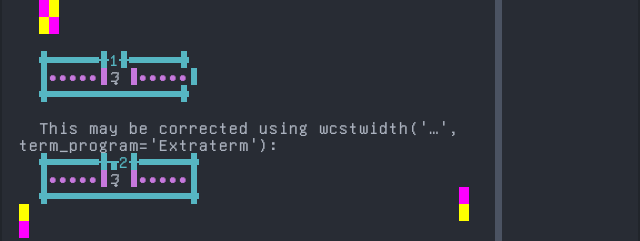
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
Tamang, Eastern
Sequence of language Tamang, Eastern from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
|
2 |
‘\u094d’ |
Mn |
0 |
DEVANAGARI SIGN VIRAMA |
|
3 |
‘\u0924’ |
Lo |
1 |
DEVANAGARI LETTER TA |
|
4 |
‘\u093f’ |
Mc |
0 |
DEVANAGARI VOWEL SIGN I |
Total codepoints: 4
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa4\x95\xe0\xa5\x8d\xe0\xa4\xa4\xe0\xa4\xbf|\\n12|\\n" क्ति| 12|
Screenshot:
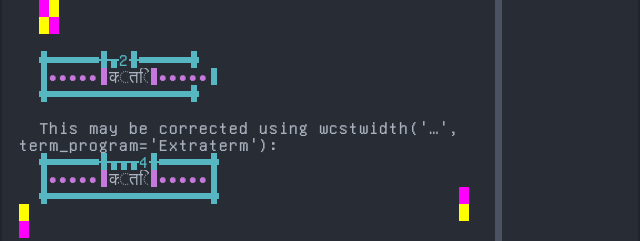
Sinhala
Sequence of language Sinhala from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0daf’ |
Lo |
1 |
SINHALA LETTER ALPAPRAANA DAYANNA |
|
2 |
‘\u0dd2’ |
Mn |
0 |
SINHALA VOWEL SIGN KETTI IS-PILLA |
|
3 |
‘\u0d82’ |
Mc |
0 |
SINHALA SIGN ANUSVARAYA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xb6\xaf\xe0\xb7\x92\xe0\xb6\x82|\\n12|\\n" දිං| 12|
Screenshot:

python wcwidth.wcswidth() measures width 2, while Extraterm measures width 3.
Kannada
Sequence of language Kannada from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0c95’ |
Lo |
1 |
KANNADA LETTER KA |
|
2 |
‘\u0cbe’ |
Mc |
0 |
KANNADA VOWEL SIGN AA |
|
3 |
‘\u0c82’ |
Mc |
0 |
KANNADA SIGN ANUSVARA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xb2\x95\xe0\xb2\xbe\xe0\xb2\x82|\\n12|\\n" ಕಾಂ| 12|
Screenshot:

python wcwidth.wcswidth() measures width 2, while Extraterm measures width 3.
Urdu (2)
Sequence of language Urdu (2) from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0627’ |
Lo |
1 |
ARABIC LETTER ALEF |
|
2 |
‘\u064b’ |
Mn |
0 |
ARABIC FATHATAN |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xd8\xa7\xd9\x8b|\\n1|\\n" اً| 1|
Screenshot:
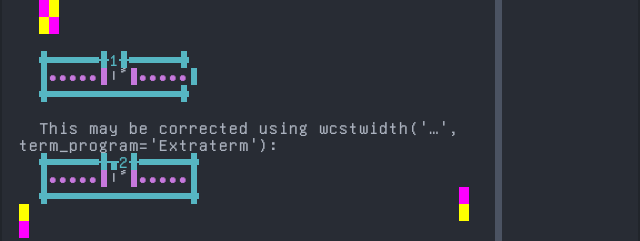
Sanskrit (Grantha)
Sequence of language Sanskrit (Grantha) from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\U00011315’ |
Lo |
1 |
GRANTHA LETTER KA |
|
2 |
‘\U0001133e’ |
Mc |
0 |
GRANTHA VOWEL SIGN AA |
|
3 |
‘\U00011302’ |
Mc |
0 |
GRANTHA SIGN ANUSVARA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xf0\x91\x8c\x95\xf0\x91\x8c\xbe\xf0\x91\x8c\x82|\\n12|\\n" 𑌕𑌾𑌂| 12|
Screenshot:

python wcwidth.wcswidth() measures width 2, while Extraterm measures width 3.
Lingala (tones)
Sequence of language Lingala (tones) from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘E’ |
Lu |
1 |
LATIN CAPITAL LETTER E |
|
2 |
‘\u0301’ |
Mn |
0 |
COMBINING ACUTE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "E\xcc\x81|\\n1|\\n" É| 1|
Screenshot:
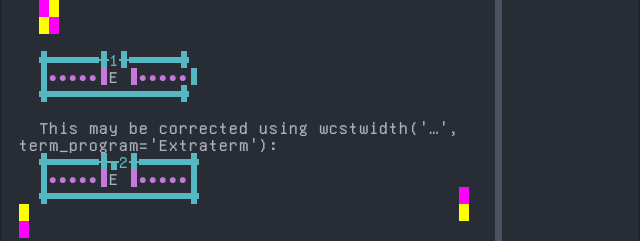
Pular (Adlam)
Sequence of language Pular (Adlam) from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\U0001e900’ |
Lu |
1 |
ADLAM CAPITAL LETTER ALIF |
|
2 |
‘\U0001e944’ |
Mn |
0 |
ADLAM ALIF LENGTHENER |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xf0\x9e\xa4\x80\xf0\x9e\xa5\x84|\\n1|\\n" 𞤀𞥄| 1|
Screenshot:
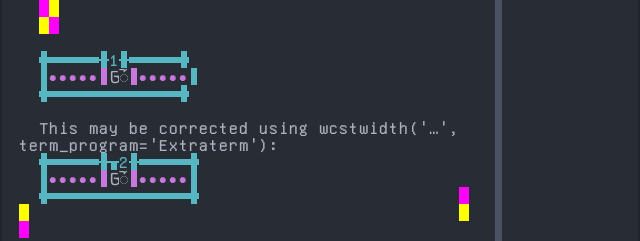
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
Urdu
Sequence of language Urdu from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0627’ |
Lo |
1 |
ARABIC LETTER ALEF |
|
2 |
‘\u064b’ |
Mn |
0 |
ARABIC FATHATAN |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xd8\xa7\xd9\x8b|\\n1|\\n" اً| 1|
Screenshot:
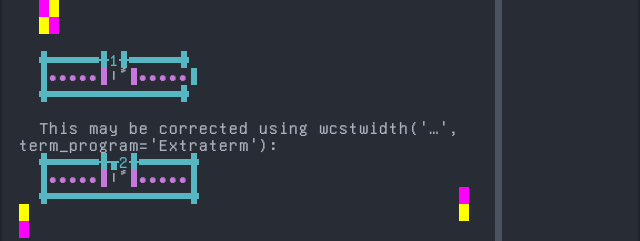
Bamun
Sequence of language Bamun from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘E’ |
Lu |
1 |
LATIN CAPITAL LETTER E |
|
2 |
‘\u0301’ |
Mn |
0 |
COMBINING ACUTE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "E\xcc\x81|\\n1|\\n" É| 1|
Screenshot:
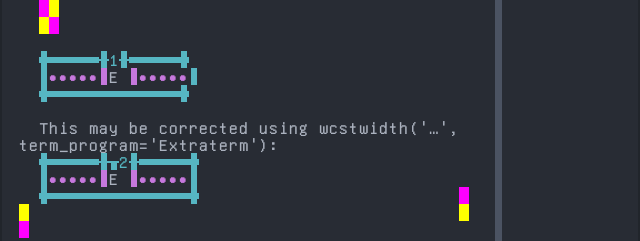
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
Ticuna
Sequence of language Ticuna from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘a’ |
Ll |
1 |
LATIN SMALL LETTER A |
|
2 |
‘\u0303’ |
Mn |
0 |
COMBINING TILDE |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "a\xcc\x83|\\n1|\\n" ã| 1|
Screenshot:
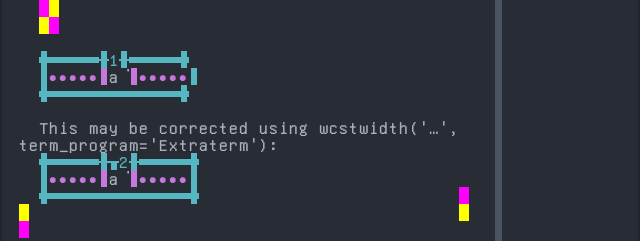
Farsi, Western
Sequence of language Farsi, Western from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0627’ |
Lo |
1 |
ARABIC LETTER ALEF |
|
2 |
‘\u064b’ |
Mn |
0 |
ARABIC FATHATAN |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xd8\xa7\xd9\x8b|\\n1|\\n" اً| 1|
Screenshot:
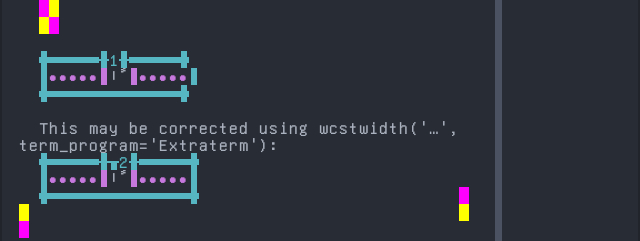
Assyrian Neo-Aramaic
Sequence of language Assyrian Neo-Aramaic from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0712’ |
Lo |
1 |
SYRIAC LETTER BETH |
|
2 |
‘\u0742’ |
Mn |
0 |
SYRIAC RUKKAKHA |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xdc\x92\xdd\x82|\\n1|\\n" ܒ݂| 1|
Screenshot:
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
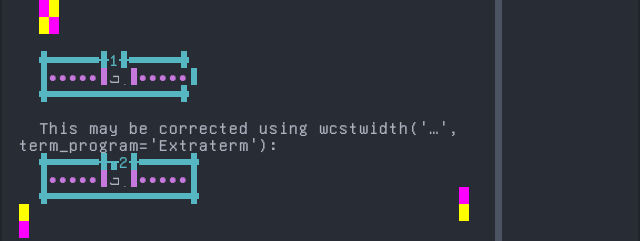
Yiddish, Eastern
Sequence of language Yiddish, Eastern from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u05d0’ |
Lo |
1 |
HEBREW LETTER ALEF |
|
2 |
‘\u05b7’ |
Mn |
0 |
HEBREW POINT PATAH |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xd7\x90\xd6\xb7|\\n1|\\n" אַ| 1|
Screenshot:
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
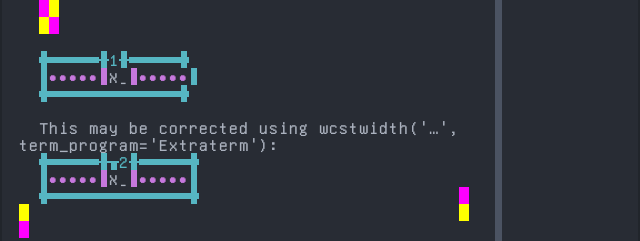
Evenki
Sequence of language Evenki from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0430’ |
Ll |
1 |
CYRILLIC SMALL LETTER A |
|
2 |
‘\u0304’ |
Mn |
0 |
COMBINING MACRON |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xd0\xb0\xcc\x84|\\n1|\\n" а̄| 1|
Screenshot:
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
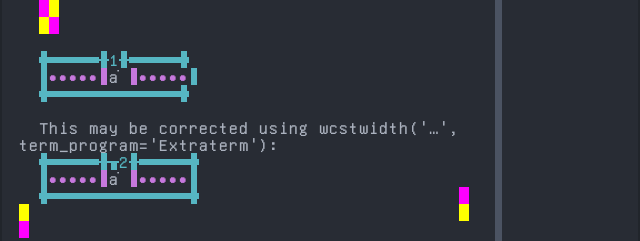
Yaneshaʼ
Sequence of language Yaneshaʼ from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘a’ |
Ll |
1 |
LATIN SMALL LETTER A |
|
2 |
‘\u0303’ |
Mn |
0 |
COMBINING TILDE |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "a\xcc\x83|\\n1|\\n" ã| 1|
Screenshot:
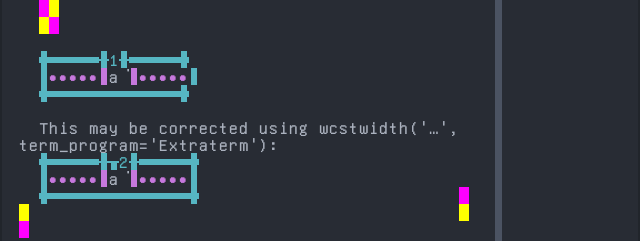
Fur
Sequence of language Fur from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘a’ |
Ll |
1 |
LATIN SMALL LETTER A |
|
2 |
‘\u0331’ |
Mn |
0 |
COMBINING MACRON BELOW |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "a\xcc\xb1|\\n1|\\n" a̱| 1|
Screenshot:
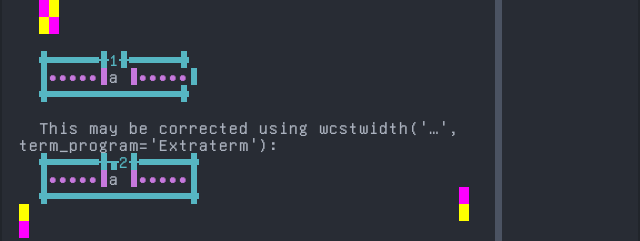
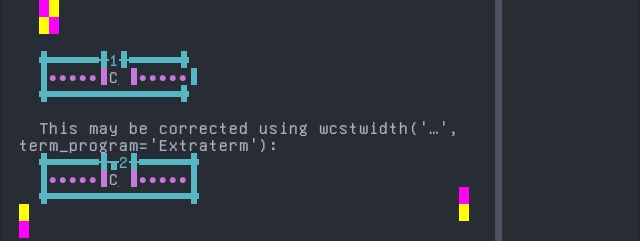
South Azerbaijani
Sequence of language South Azerbaijani from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘C’ |
Lu |
1 |
LATIN CAPITAL LETTER C |
|
2 |
‘\u0327’ |
Mn |
0 |
COMBINING CEDILLA |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "C\xcc\xa7|\\n1|\\n" Ç| 1|
Screenshot:
Tamil
Sequence of language Tamil from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0b95’ |
Lo |
1 |
TAMIL LETTER KA |
|
2 |
‘\u0bc0’ |
Mn |
0 |
TAMIL VOWEL SIGN II |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xae\x95\xe0\xaf\x80|\\n1|\\n" கீ| 1|
Screenshot:
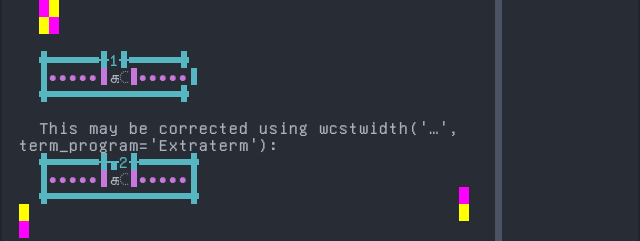
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
Tamil (Sri Lanka)
Sequence of language Tamil (Sri Lanka) from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0b95’ |
Lo |
1 |
TAMIL LETTER KA |
|
2 |
‘\u0bc0’ |
Mn |
0 |
TAMIL VOWEL SIGN II |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xae\x95\xe0\xaf\x80|\\n1|\\n" கீ| 1|
Screenshot:
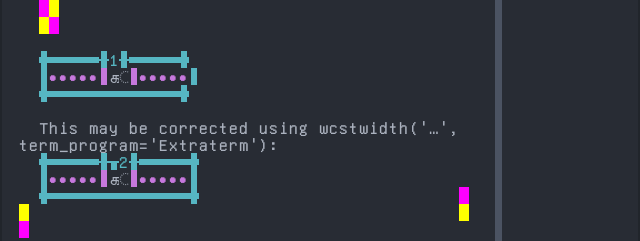
Catalan (2)
Sequence of language Catalan (2) from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘a’ |
Ll |
1 |
LATIN SMALL LETTER A |
|
2 |
‘\u0300’ |
Mn |
0 |
COMBINING GRAVE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "a\xcc\x80|\\n1|\\n" à| 1|
Screenshot:
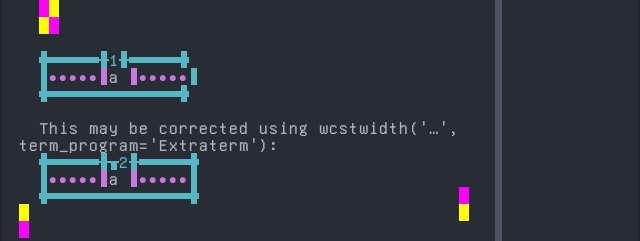
Chinantec, Chiltepec
Sequence of language Chinantec, Chiltepec from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘a’ |
Ll |
1 |
LATIN SMALL LETTER A |
|
2 |
‘\u0331’ |
Mn |
0 |
COMBINING MACRON BELOW |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "a\xcc\xb1|\\n1|\\n" a̱| 1|
Screenshot:
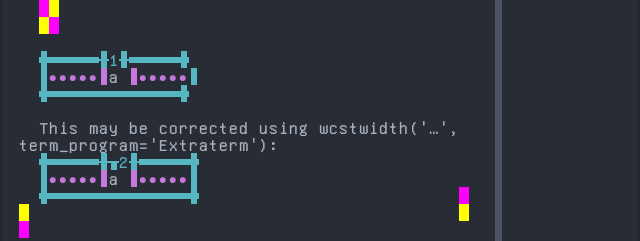
Arabic, Standard
Sequence of language Arabic, Standard from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0627’ |
Lo |
1 |
ARABIC LETTER ALEF |
|
2 |
‘\u064b’ |
Mn |
0 |
ARABIC FATHATAN |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xd8\xa7\xd9\x8b|\\n1|\\n" اً| 1|
Screenshot:
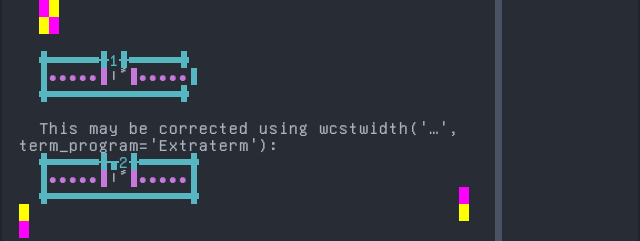
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
Chickasaw
Sequence of language Chickasaw from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘I’ |
Lu |
1 |
LATIN CAPITAL LETTER I |
|
2 |
‘\u0331’ |
Mn |
0 |
COMBINING MACRON BELOW |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "I\xcc\xb1|\\n1|\\n" I̱| 1|
Screenshot:
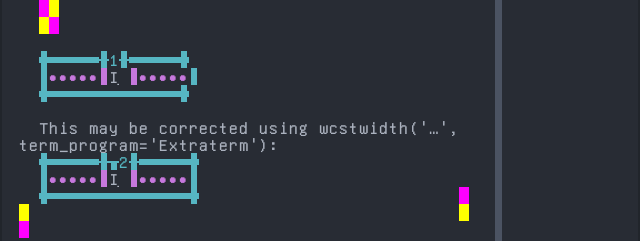
Dari
Sequence of language Dari from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0627’ |
Lo |
1 |
ARABIC LETTER ALEF |
|
2 |
‘\u064b’ |
Mn |
0 |
ARABIC FATHATAN |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xd8\xa7\xd9\x8b|\\n1|\\n" اً| 1|
Screenshot:
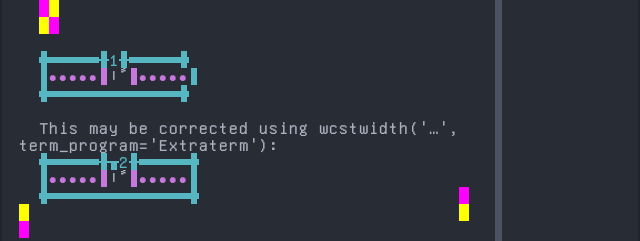
Kabyle
Sequence of language Kabyle from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘ ‘ |
Zs |
1 |
SPACE |
|
2 |
‘\u0323’ |
Mn |
0 |
COMBINING DOT BELOW |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf " \xcc\xa3|\\n1|\\n" ̣| 1|
Screenshot:
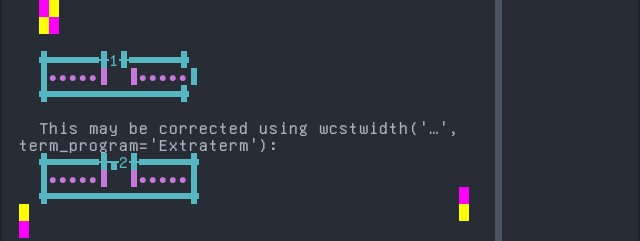
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
Tamazight, Central Atlas
Sequence of language Tamazight, Central Atlas from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘h’ |
Ll |
1 |
LATIN SMALL LETTER H |
|
2 |
‘\u0323’ |
Mn |
0 |
COMBINING DOT BELOW |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "h\xcc\xa3|\\n1|\\n" ḥ| 1|
Screenshot:
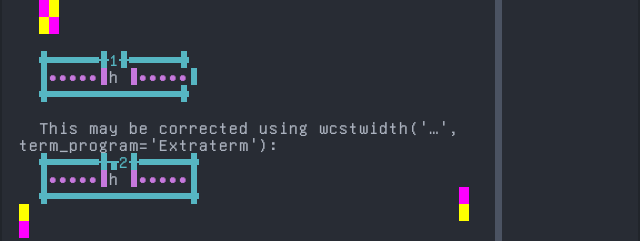
Maori (2)
Sequence of language Maori (2) from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘A’ |
Lu |
1 |
LATIN CAPITAL LETTER A |
|
2 |
‘\u0304’ |
Mn |
0 |
COMBINING MACRON |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "A\xcc\x84|\\n1|\\n" Ā| 1|
Screenshot:
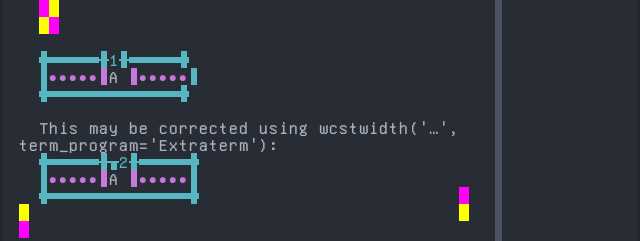
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
Mirandese
Sequence of language Mirandese from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘C’ |
Lu |
1 |
LATIN CAPITAL LETTER C |
|
2 |
‘\u0327’ |
Mn |
0 |
COMBINING CEDILLA |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "C\xcc\xa7|\\n1|\\n" Ç| 1|
Screenshot:
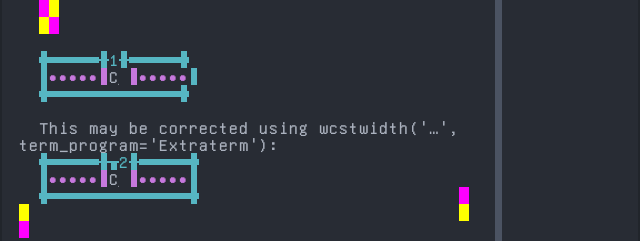
Gumuz
Sequence of language Gumuz from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘a’ |
Ll |
1 |
LATIN SMALL LETTER A |
|
2 |
‘\u0301’ |
Mn |
0 |
COMBINING ACUTE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "a\xcc\x81|\\n1|\\n" á| 1|
Screenshot:
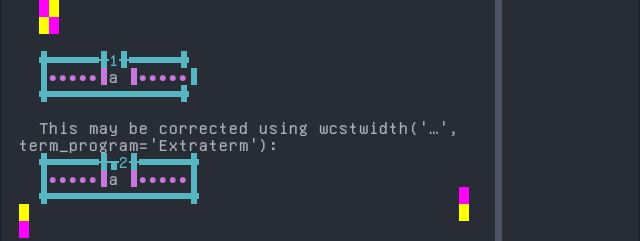
Yoruba
Sequence of language Yoruba from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘n’ |
Ll |
1 |
LATIN SMALL LETTER N |
|
2 |
‘\u0304’ |
Mn |
0 |
COMBINING MACRON |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "n\xcc\x84|\\n1|\\n" n̄| 1|
Screenshot:
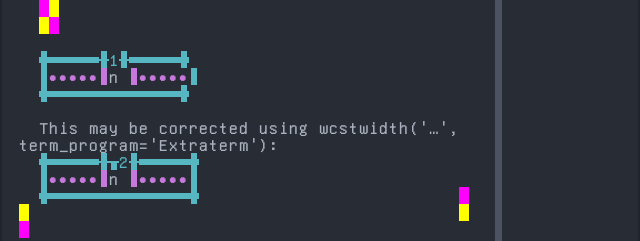
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
Siona
Sequence of language Siona from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘a’ |
Ll |
1 |
LATIN SMALL LETTER A |
|
2 |
‘\u0331’ |
Mn |
0 |
COMBINING MACRON BELOW |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "a\xcc\xb1|\\n1|\\n" a̱| 1|
Screenshot:
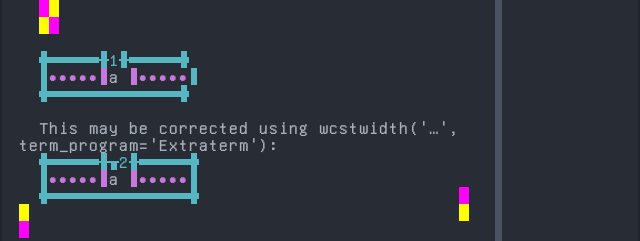
Secoya
Sequence of language Secoya from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘a’ |
Ll |
1 |
LATIN SMALL LETTER A |
|
2 |
‘\u0331’ |
Mn |
0 |
COMBINING MACRON BELOW |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "a\xcc\xb1|\\n1|\\n" a̱| 1|
Screenshot:
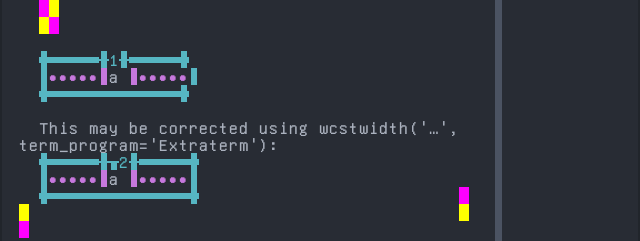
Amarakaeri
Sequence of language Amarakaeri from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘I’ |
Lu |
1 |
LATIN CAPITAL LETTER I |
|
2 |
‘\u0331’ |
Mn |
0 |
COMBINING MACRON BELOW |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "I\xcc\xb1|\\n1|\\n" I̱| 1|
Screenshot:
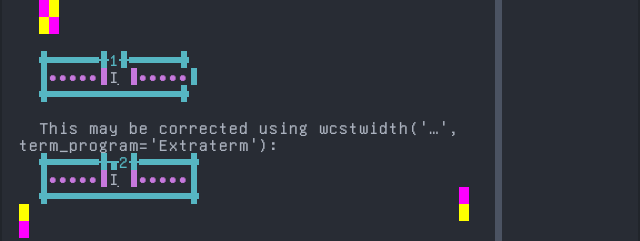
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
Nanai
Sequence of language Nanai from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0430’ |
Ll |
1 |
CYRILLIC SMALL LETTER A |
|
2 |
‘\u0304’ |
Mn |
0 |
COMBINING MACRON |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xd0\xb0\xcc\x84|\\n1|\\n" а̄| 1|
Screenshot:
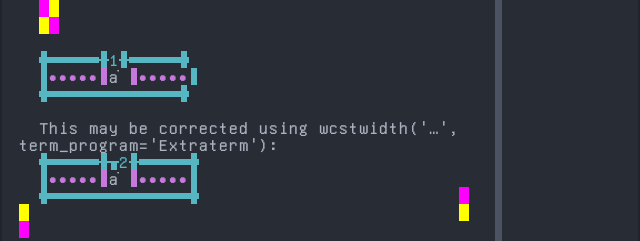
Orok
Sequence of language Orok from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0430’ |
Ll |
1 |
CYRILLIC SMALL LETTER A |
|
2 |
‘\u0304’ |
Mn |
0 |
COMBINING MACRON |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xd0\xb0\xcc\x84|\\n1|\\n" а̄| 1|
Screenshot:
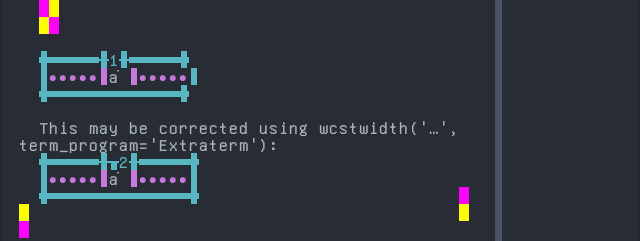
French (Welche)
Sequence of language French (Welche) from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘E’ |
Lu |
1 |
LATIN CAPITAL LETTER E |
|
2 |
‘\u0301’ |
Mn |
0 |
COMBINING ACUTE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "E\xcc\x81|\\n1|\\n" É| 1|
Screenshot:
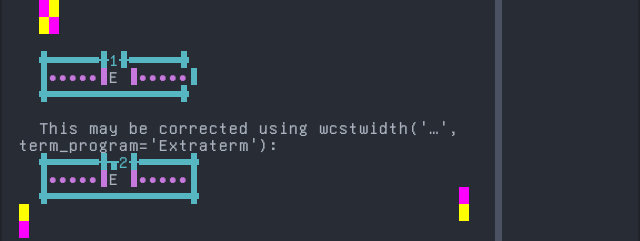
Navajo
Sequence of language Navajo from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0105’ |
Ll |
1 |
LATIN SMALL LETTER A WITH OGONEK |
|
2 |
‘\u0301’ |
Mn |
0 |
COMBINING ACUTE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xc4\x85\xcc\x81|\\n1|\\n" ą́| 1|
Screenshot:
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
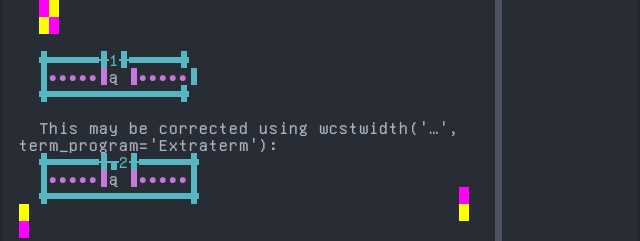
Otomi, Mezquital
Sequence of language Otomi, Mezquital from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘O’ |
Lu |
1 |
LATIN CAPITAL LETTER O |
|
2 |
‘\u0331’ |
Mn |
0 |
COMBINING MACRON BELOW |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "O\xcc\xb1|\\n1|\\n" O̱| 1|
Screenshot:
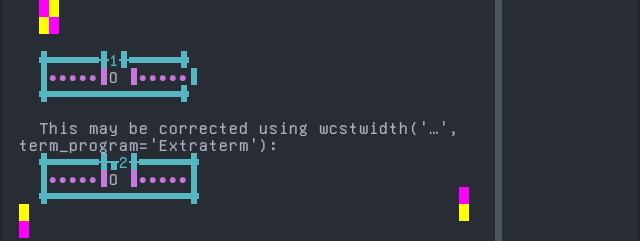
Saint Lucian Creole French
Sequence of language Saint Lucian Creole French from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘e’ |
Ll |
1 |
LATIN SMALL LETTER E |
|
2 |
‘\u0300’ |
Mn |
0 |
COMBINING GRAVE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "e\xcc\x80|\\n1|\\n" è| 1|
Screenshot:
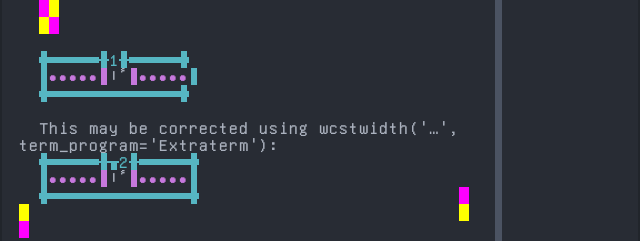
Baatonum
Sequence of language Baatonum from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0254’ |
Ll |
1 |
LATIN SMALL LETTER OPEN O |
|
2 |
‘\u0300’ |
Mn |
0 |
COMBINING GRAVE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xc9\x94\xcc\x80|\\n1|\\n" ɔ̀| 1|
Screenshot:
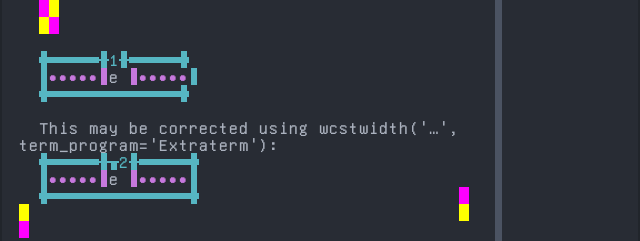
Panjabi, Western
Sequence of language Panjabi, Western from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0627’ |
Lo |
1 |
ARABIC LETTER ALEF |
|
2 |
‘\u0654’ |
Mn |
0 |
ARABIC HAMZA ABOVE |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xd8\xa7\xd9\x94|\\n1|\\n" أ| 1|
Screenshot:
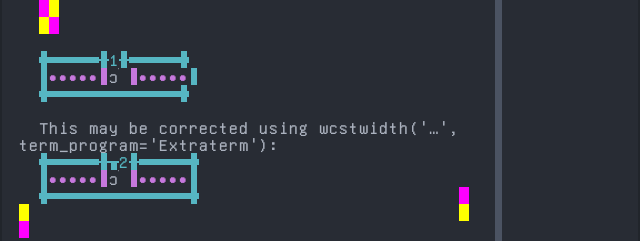
Éwé
Sequence of language Éwé from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘a’ |
Ll |
1 |
LATIN SMALL LETTER A |
|
2 |
‘\u0303’ |
Mn |
0 |
COMBINING TILDE |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "a\xcc\x83|\\n1|\\n" ã| 1|
Screenshot:
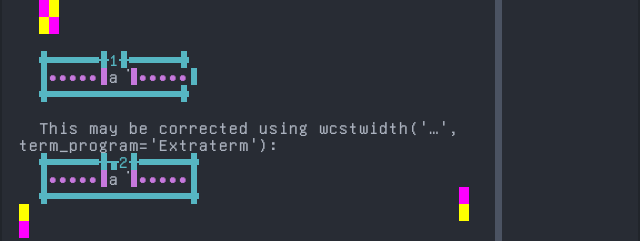
Mixtec, Metlatónoc
Sequence of language Mixtec, Metlatónoc from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘a’ |
Ll |
1 |
LATIN SMALL LETTER A |
|
2 |
‘\u0331’ |
Mn |
0 |
COMBINING MACRON BELOW |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "a\xcc\xb1|\\n1|\\n" a̱| 1|
Screenshot:
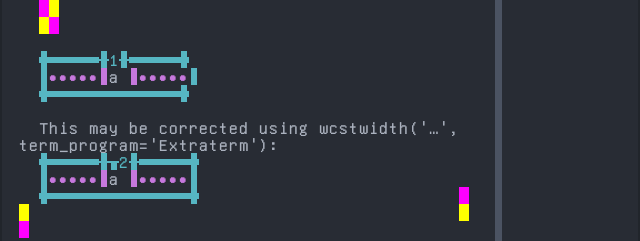
Mazahua Central
Sequence of language Mazahua Central from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘e’ |
Ll |
1 |
LATIN SMALL LETTER E |
|
2 |
‘\u0331’ |
Mn |
0 |
COMBINING MACRON BELOW |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "e\xcc\xb1|\\n1|\\n" e̱| 1|
Screenshot:
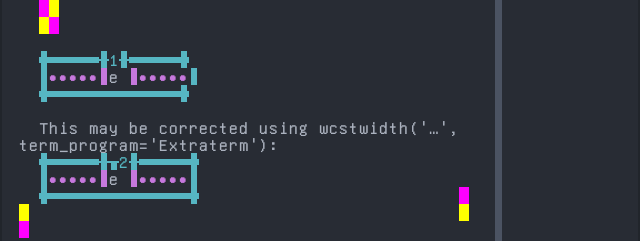
Tem
Sequence of language Tem from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0254’ |
Ll |
1 |
LATIN SMALL LETTER OPEN O |
|
2 |
‘\u0301’ |
Mn |
0 |
COMBINING ACUTE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xc9\x94\xcc\x81|\\n1|\\n" ɔ́| 1|
Screenshot:
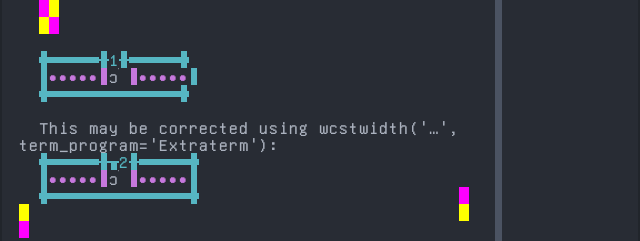
Gen
Sequence of language Gen from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘n’ |
Ll |
1 |
LATIN SMALL LETTER N |
|
2 |
‘\u0300’ |
Mn |
0 |
COMBINING GRAVE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "n\xcc\x80|\\n1|\\n" ǹ| 1|
Screenshot:
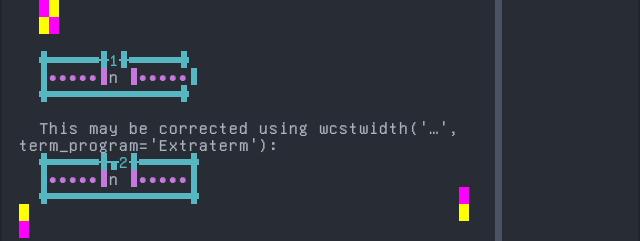
Waama
Sequence of language Waama from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘n’ |
Ll |
1 |
LATIN SMALL LETTER N |
|
2 |
‘\u0300’ |
Mn |
0 |
COMBINING GRAVE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "n\xcc\x80|\\n1|\\n" ǹ| 1|
Screenshot:
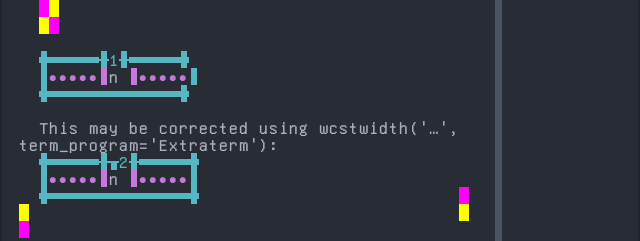
Uduk
Sequence of language Uduk from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘c’ |
Ll |
1 |
LATIN SMALL LETTER C |
|
2 |
‘\u0331’ |
Mn |
0 |
COMBINING MACRON BELOW |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "c\xcc\xb1|\\n1|\\n" c̱| 1|
Screenshot:
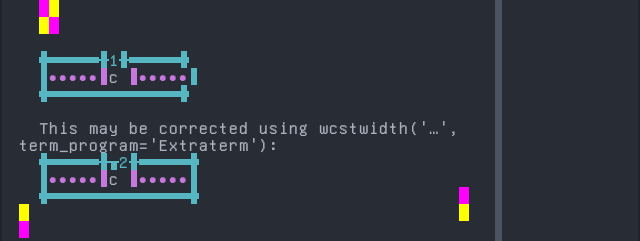
Ga
Sequence of language Ga from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0254’ |
Ll |
1 |
LATIN SMALL LETTER OPEN O |
|
2 |
‘\u0303’ |
Mn |
0 |
COMBINING TILDE |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xc9\x94\xcc\x83|\\n1|\\n" ɔ̃| 1|
Screenshot:
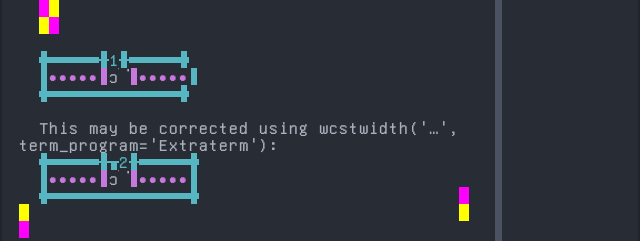
Dagaare, Southern
Sequence of language Dagaare, Southern from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘u’ |
Ll |
1 |
LATIN SMALL LETTER U |
|
2 |
‘\u0303’ |
Mn |
0 |
COMBINING TILDE |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "u\xcc\x83|\\n1|\\n" ũ| 1|
Screenshot:
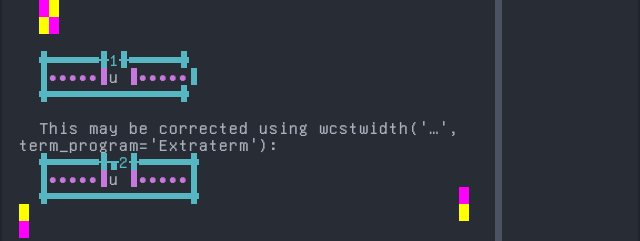
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
Fon
Sequence of language Fon from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0254’ |
Ll |
1 |
LATIN SMALL LETTER OPEN O |
|
2 |
‘\u0300’ |
Mn |
0 |
COMBINING GRAVE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xc9\x94\xcc\x80|\\n1|\\n" ɔ̀| 1|
Screenshot:
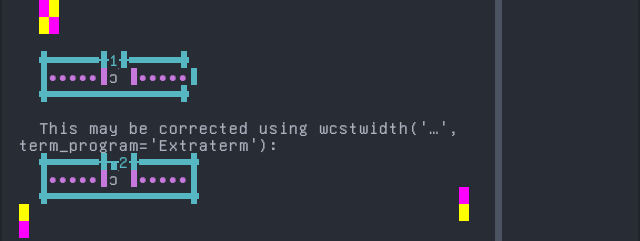
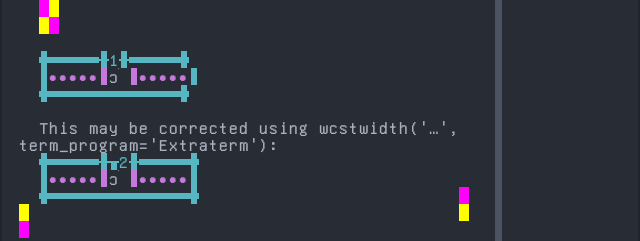
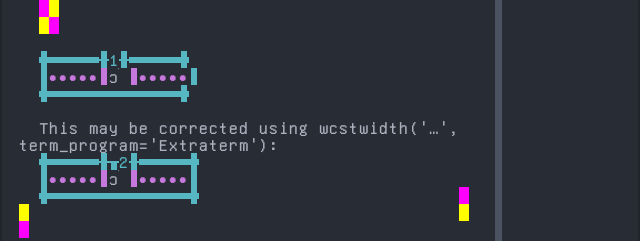
Lamnso’
Sequence of language Lamnso’ from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘k’ |
Ll |
1 |
LATIN SMALL LETTER K |
|
2 |
‘\u0300’ |
Mn |
0 |
COMBINING GRAVE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "k\xcc\x80|\\n1|\\n" k̀| 1|
Screenshot:
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
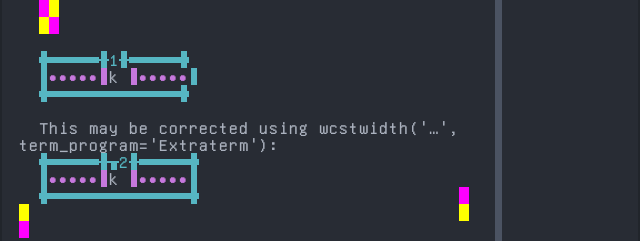
Aja
Sequence of language Aja from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0254’ |
Ll |
1 |
LATIN SMALL LETTER OPEN O |
|
2 |
‘\u0300’ |
Mn |
0 |
COMBINING GRAVE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xc9\x94\xcc\x80|\\n1|\\n" ɔ̀| 1|
Screenshot:
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
Dinka, Northeastern
Sequence of language Dinka, Northeastern from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0254’ |
Ll |
1 |
LATIN SMALL LETTER OPEN O |
|
2 |
‘\u0308’ |
Mn |
0 |
COMBINING DIAERESIS |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xc9\x94\xcc\x88|\\n1|\\n" ɔ̈| 1|
Screenshot:
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
Belanda Viri
Sequence of language Belanda Viri from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\xe4’ |
Ll |
1 |
LATIN SMALL LETTER A WITH DIAERESIS |
|
2 |
‘\u0301’ |
Mn |
0 |
COMBINING ACUTE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xc3\xa4\xcc\x81|\\n1|\\n" ä́| 1|
Screenshot:
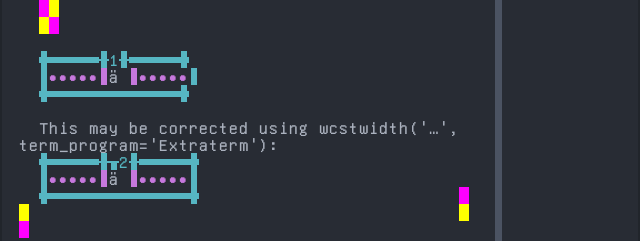
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
Bora
Sequence of language Bora from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0197’ |
Lu |
1 |
LATIN CAPITAL LETTER I WITH STROKE |
|
2 |
‘\u0301’ |
Mn |
0 |
COMBINING ACUTE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xc6\x97\xcc\x81|\\n1|\\n" Ɨ́| 1|
Screenshot:
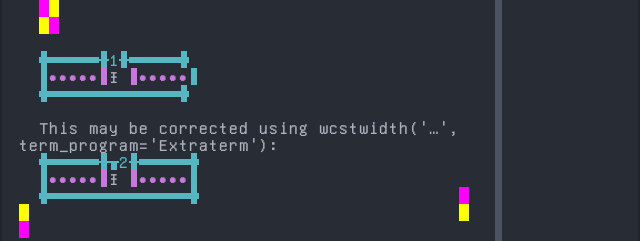
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
Ditammari
Sequence of language Ditammari from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0254’ |
Ll |
1 |
LATIN SMALL LETTER OPEN O |
|
2 |
‘\u0303’ |
Mn |
0 |
COMBINING TILDE |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xc9\x94\xcc\x83|\\n1|\\n" ɔ̃| 1|
Screenshot:
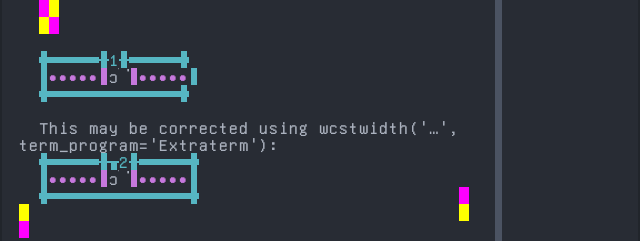
Pashto, Northern
Sequence of language Pashto, Northern from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0627’ |
Lo |
1 |
ARABIC LETTER ALEF |
|
2 |
‘\u064b’ |
Mn |
0 |
ARABIC FATHATAN |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xd8\xa7\xd9\x8b|\\n1|\\n" اً| 1|
Screenshot:
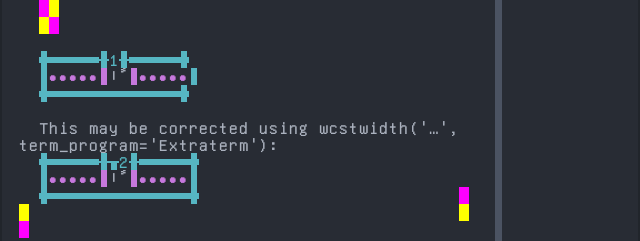
Seraiki
Sequence of language Seraiki from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0627’ |
Lo |
1 |
ARABIC LETTER ALEF |
|
2 |
‘\u064f’ |
Mn |
0 |
ARABIC DAMMA |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xd8\xa7\xd9\x8f|\\n1|\\n" اُ| 1|
Screenshot:
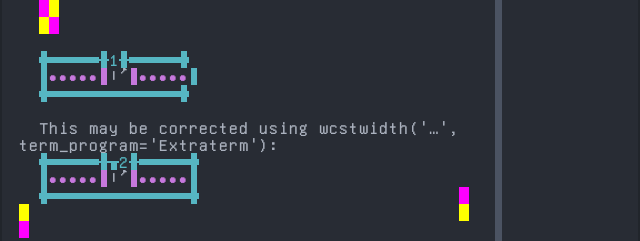
Shipibo-Conibo
Sequence of language Shipibo-Conibo from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘S’ |
Lu |
1 |
LATIN CAPITAL LETTER S |
|
2 |
‘\u0308’ |
Mn |
0 |
COMBINING DIAERESIS |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "S\xcc\x88|\\n1|\\n" S̈| 1|
Screenshot:
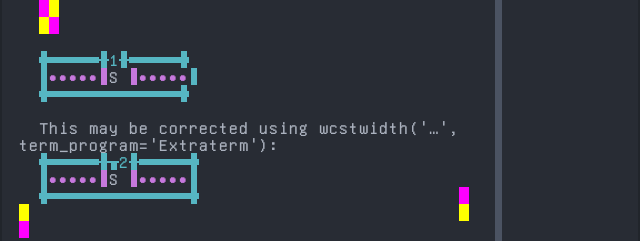
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
Dendi
Sequence of language Dendi from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0254’ |
Ll |
1 |
LATIN SMALL LETTER OPEN O |
|
2 |
‘\u0303’ |
Mn |
0 |
COMBINING TILDE |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xc9\x94\xcc\x83|\\n1|\\n" ɔ̃| 1|
Screenshot:
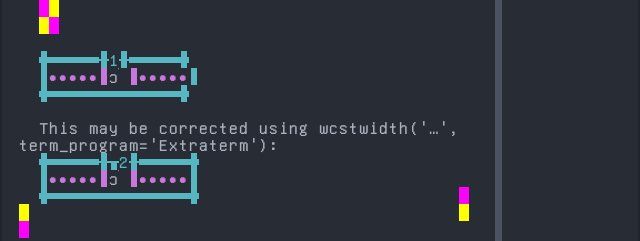
Gilyak
Sequence of language Gilyak from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0420’ |
Lu |
1 |
CYRILLIC CAPITAL LETTER ER |
|
2 |
‘\u030c’ |
Mn |
0 |
COMBINING CARON |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xd0\xa0\xcc\x8c|\\n1|\\n" Р̌| 1|
Screenshot:
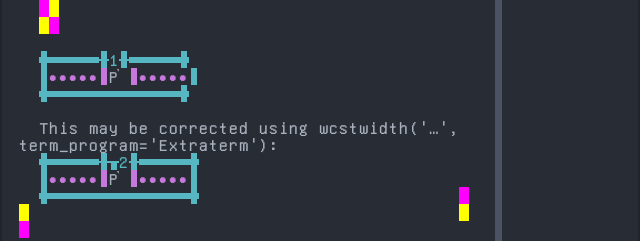
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
Picard
Sequence of language Picard from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘e’ |
Ll |
1 |
LATIN SMALL LETTER E |
|
2 |
‘\u030a’ |
Mn |
0 |
COMBINING RING ABOVE |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "e\xcc\x8a|\\n1|\\n" e̊| 1|
Screenshot:
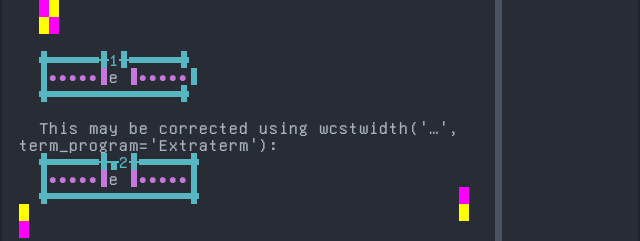
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
Dangme
Sequence of language Dangme from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0254’ |
Ll |
1 |
LATIN SMALL LETTER OPEN O |
|
2 |
‘\u0301’ |
Mn |
0 |
COMBINING ACUTE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xc9\x94\xcc\x81|\\n1|\\n" ɔ́| 1|
Screenshot:
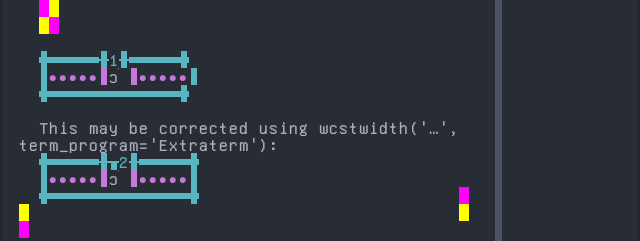
Veps
Sequence of language Veps from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘u’ |
Ll |
1 |
LATIN SMALL LETTER U |
|
2 |
‘\u0308’ |
Mn |
0 |
COMBINING DIAERESIS |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "u\xcc\x88|\\n1|\\n" ü| 1|
Screenshot:
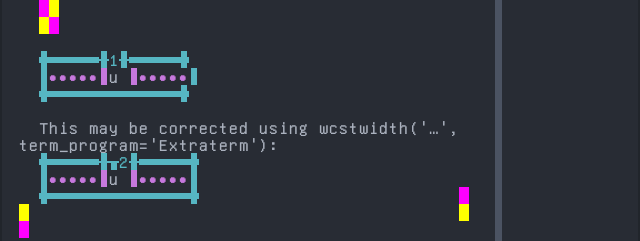
Mòoré
Sequence of language Mòoré from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘e’ |
Ll |
1 |
LATIN SMALL LETTER E |
|
2 |
‘\u0303’ |
Mn |
0 |
COMBINING TILDE |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "e\xcc\x83|\\n1|\\n" ẽ| 1|
Screenshot:
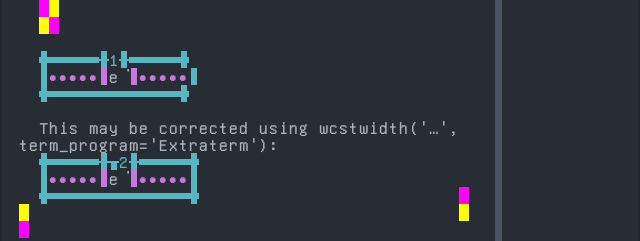
python wcwidth.wcswidth() measures width 1, while Extraterm measures width 2.
DEC Private Modes Support
This Terminal does not appear capable of reporting about any DEC Private modes.
Kitty Keyboard Protocol
Extraterm does not support the Kitty keyboard protocol.
XTGETTCAP (Terminfo Capabilities)
Extraterm does not support the XTGETTCAP sequence.
Text Sizing Protocol (OSC 66)
Extraterm does not support the Text Sizing protocol.
Truecolor Support
Extraterm supports 24-bit truecolor, detectable via:
XTGETTCAP (RGB capability): no
DECRQSS (truecolor probe): no
COLORTERM: yes (truecolor)
Warning
COLORTERM is an environment variable, not a terminal query. It is not forwarded over SSH without SendEnv / AcceptEnv configuration, so detection via COLORTERM alone may be unreliable on remote hosts.
OSC 52 Clipboard Support
Extraterm does not advertise OSC 52 clipboard support via DA1 extension 52 or XTGETTCAP Ms.
DA1 extension 52: no
XTGETTCAP Ms: no
Terminal Identification
Extraterm is identified as Extraterm version 0.81.4 (detected via ENQ).
XTVERSION: no
XTGETTCAP TN: no
ENQ: yes
TERM_PROGRAM: no
TERM: no (xterm-256color)
Reproduction
To reproduce these results for Extraterm, install and run ucs-detect with the following commands:
uvx ucs-detect --rerun data/extraterm.yaml
Test Performance
The test suite completed in 307.73 seconds (307s).
Mean CPU: 30.9%
Mean RSS: 351.6 MB
Total time: 307.7s
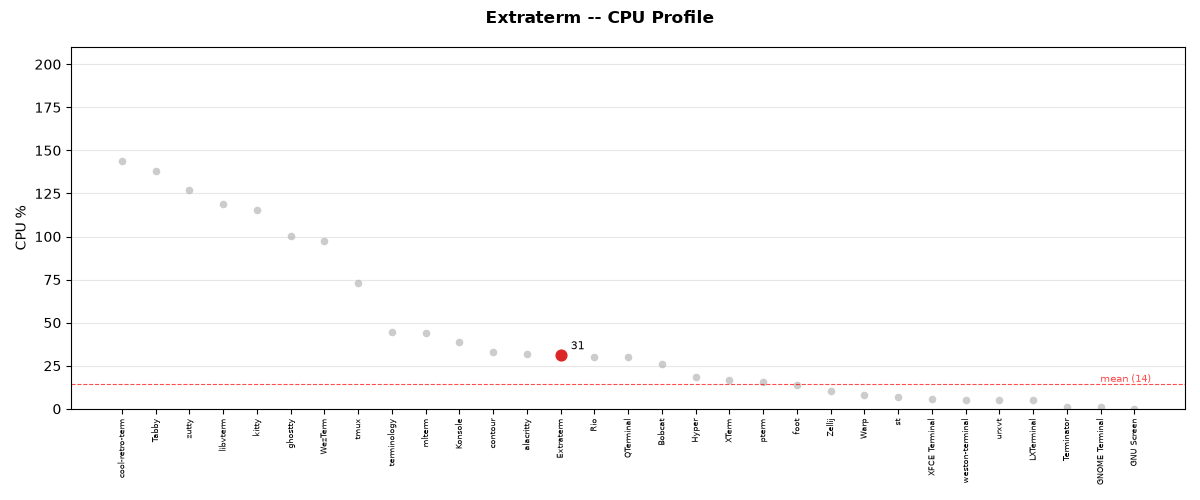
CPU usage during test execution for Extraterm.
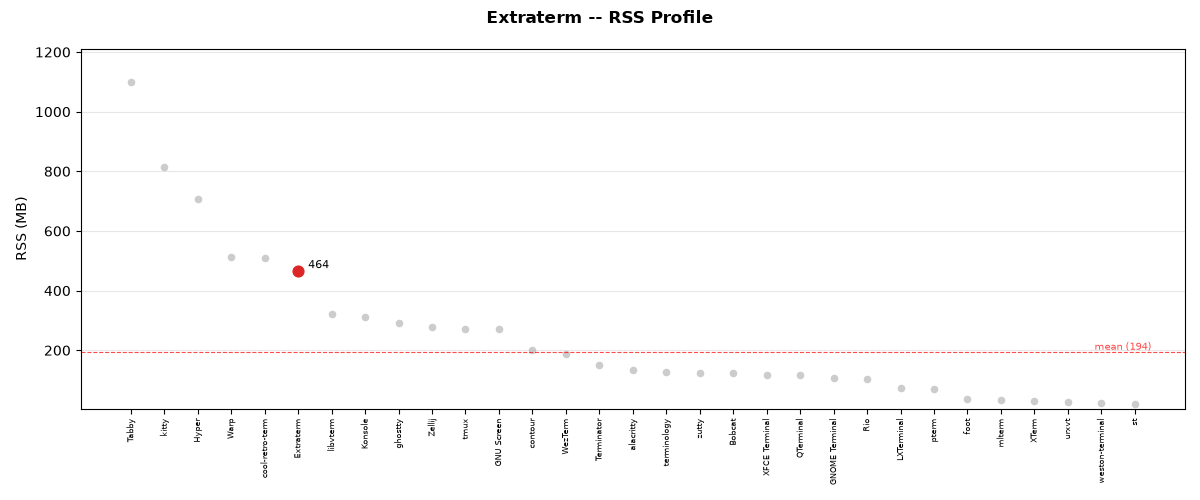
RSS memory usage during test execution for Extraterm.
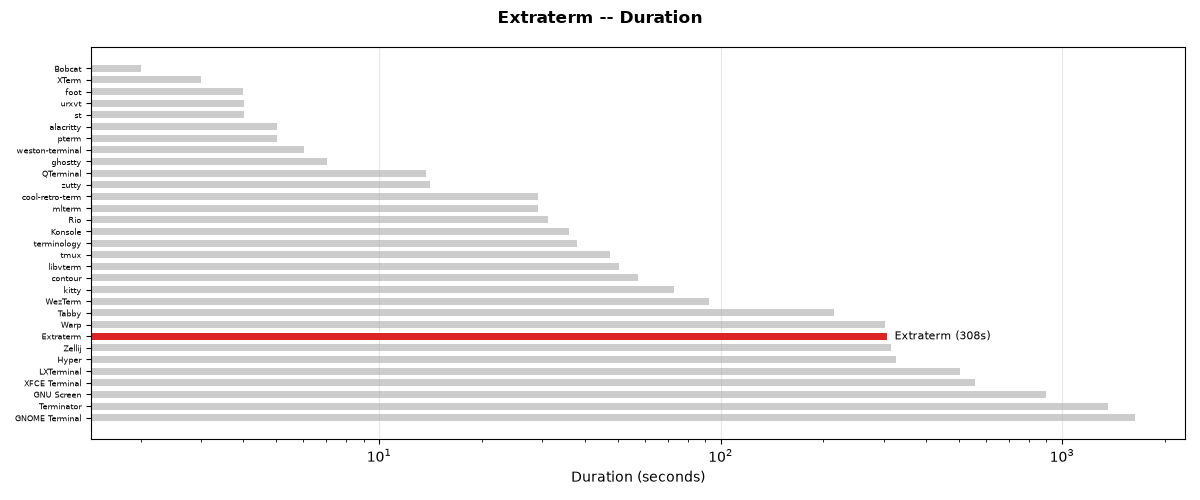
Test duration for Extraterm compared to all other terminals.
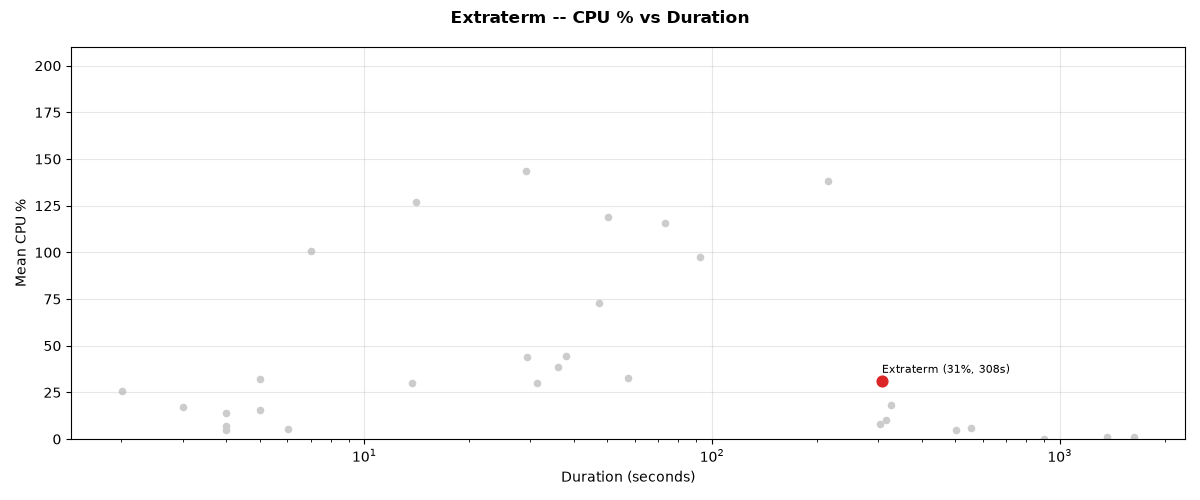
CPU % vs duration trade-off for Extraterm.