weston-terminal
Tested Software version 15.0.1-1 on Linux. The homepage URL of this terminal is https://gitlab.freedesktop.org/wayland/weston. Full results available at ucs-detect repository path data/westonterminal.yaml.
Score Breakdown
Detailed breakdown of how scores are calculated for weston-terminal:
# |
Score Type |
Raw Score |
Final Scaled Score |
|---|---|---|---|
1 |
88.07% |
83.1% |
|
2 |
0.00% |
0.0% |
|
3 |
0.00% |
0.0% |
|
4 |
0.09% |
0.0% |
|
5 |
100.00% |
100.0% |
|
6 |
0.00% |
(excluded) |
|
7 |
0.00% |
0.0% |
|
8 |
100.00% |
100.0% |
|
9 |
98.85% |
98.9% |
|
10 |
0.00% |
0.0% |
|
11 |
0% |
0.0% |
|
12 |
96.6% |
96.6% |
Score Comparison Plot:
The following plot shows how this terminal’s scores compare to all other terminals tested.
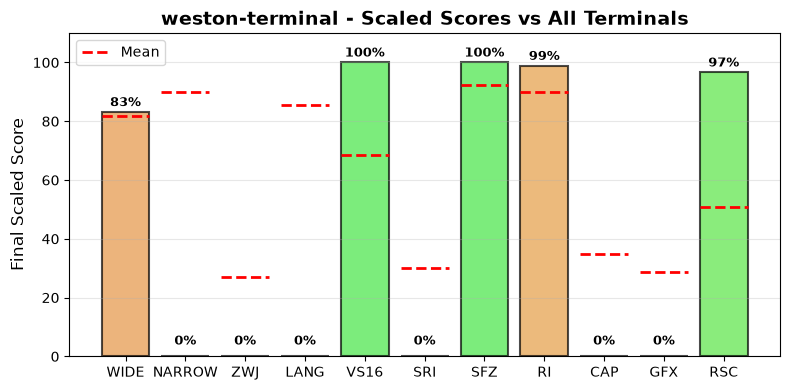
Scaled scores comparison across all metrics (normalized 0-100%)
Final Scaled Score Calculation:
Raw Final Score: 38.14% (weighted average: WIDE + NARROW + ZWJ + LANG + VS16 + 0.33 * SRI + 0.33 * SFZ + RI + CAP + 0.5 * GFX + 0.5 * RSC) the categorized ‘average’ absolute support level of this terminal.
Note
RSC (Resources) is a composite CPU, memory, and runtime score. RSC is weighted at 0.5 (half as powerful as other metrics). FEAT (Features) is the fraction of notable features supported. GFX (Graphics) scores 100% for modern protocols (iTerm2, Kitty), 50% for legacy only (Sixel, ReGIS), 0% for none.
Final Scaled Score: 6.9% (normalized across all terminals tested). Final Scaled scores are normalized (0-100%) relative to all terminals tested
WIDE Score Details:
Wide character support calculation:
Total successful codepoints: 487
Total codepoints tested: 553
Formula: 487 / 553
Result: 88.07%
NARROW Score Details:
No NARROW character support detected.
ZWJ Score Details:
Emoji ZWJ (Zero-Width Joiner) support calculation:
Total successful sequences: 0
Total sequences tested: 1445
Formula: 0 / 1445
Result: 0.00%
VS16 Score Details:
Variation Selector-16 support calculation:
Errors: 0 of 426 codepoints tested
Success rate: 100.0%
Formula: 100.0 / 100
Result: 100.00%
VS15 Score Details (excluded from final score):
Variation Selector-15 support calculation:
Errors: 158 of 158 codepoints tested
Success rate: 0.0%
Formula: 0.0 / 100
Result: 0.00%
SRI Score Details:
Standalone Regional Indicator support calculation:
Total successful codepoints: 0
Total codepoints tested: 26
Formula: 0 / 26
Result: 0.00%
SFZ Score Details:
Standalone Fitzpatrick skin tone modifier support calculation:
Total successful codepoints: 5
Total codepoints tested: 5
Formula: 5 / 5
Result: 100.00%
RI Score Details:
Regional Indicator flag sequence support calculation:
Total successful sequences: 259
Total sequences tested: 262
Formula: 259 / 262
Result: 98.85%
Features Score Details:
Notable terminal features (0.0 / 16):
Kitty Keyboard: no
XTGETTCAP: no
OSC 52 Clipboard: no
Raw score: 0.00%
Graphics Score Details:
Graphics protocol support (0%):
Sixel: no
ReGIS: no
iTerm2: no
Kitty: no
Scoring: 100% for modern (iTerm2/Kitty), 50% for legacy only (Sixel/ReGIS), 0% for none
Resource Score Details:
Duration: 6.0s
Mean CPU: 5.3%
Mean RSS: 22.3 MB
Resources Score: 97/100
Note: log-scale composite cost = log(CPU+1) + log(RSS+1) + log(time+1)
Scaled result: 96.6%
LANG Score Details (Geometric Mean):
Geometric mean calculation:
Formula: (p₁ × p₂ × … × pₙ)^(1/n) where n = 85 languages
About geometric mean
Result: 0.09%
Wide character support
Wide character support of weston-terminal is 88.1% (66 errors of 553 codepoints tested).
Sequence of a WIDE character, from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\ufaf9’ |
Cn |
2 |
na |
Total codepoints: 1
Shell test using printf(1),
'|'should align in output:$ printf "\xef\xab\xb9|\\n12|\\n" | 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 1.
Narrow character support
Narrow character results for weston-terminal are not available.
Emoji ZWJ support
Compatibility of weston-terminal with the Unicode Emoji ZWJ sequence table is 0.0% (1445 errors of 1445 sequences tested).
Sequence of an Emoji ZWJ Sequence, from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\U0001f482’ |
So |
2 |
GUARDSMAN |
|
2 |
‘\U0001f3fd’ |
Sk |
2 |
EMOJI MODIFIER FITZPATRICK TYPE-4 |
|
3 |
‘\u200d’ |
Cf |
0 |
ZERO WIDTH JOINER |
|
4 |
‘\u2640’ |
So |
1 |
FEMALE SIGN |
|
5 |
‘\ufe0f’ |
Mn |
0 |
VARIATION SELECTOR-16 |
Total codepoints: 5
Shell test using printf(1),
'|'should align in output:$ printf "\xf0\x9f\x92\x82\xf0\x9f\x8f\xbd\xe2\x80\x8d\xe2\x99\x80\xef\xb8\x8f|\\n12|\\n" 💂🏽♀️| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 7.
Variation Selector-16 support
Emoji VS-16 results for weston-terminal is 0 errors out of 426 total codepoints tested, 100.0% success. All codepoint combinations with Variation Selector-16 tested were successful.
Variation Selector-15 support
Emoji VS-15 results for weston-terminal is 158 errors out of 158 total codepoints tested, 0.0% success. Sequence of a WIDE Emoji made NARROW by Variation Selector-15, from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\U0001f3ae’ |
So |
2 |
VIDEO GAME |
|
2 |
‘\ufe0e’ |
Mn |
0 |
VARIATION SELECTOR-15 |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xf0\x9f\x8e\xae\xef\xb8\x8e|\\n1|\\n" 🎮︎| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 3.
Standalone Regional Indicator support
Standalone Regional Indicator support of weston-terminal is 0.0% (26 errors of 26 codepoints tested).
Sequence of a standalone Regional Indicator, from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\U0001f1f3’ |
So |
2 |
REGIONAL INDICATOR SYMBOL LETTER N |
Total codepoints: 1
Shell test using printf(1),
'|'should align in output:$ printf "\xf0\x9f\x87\xb3|\\n12|\\n" 🇳| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 1.
Standalone Fitzpatrick modifier support
Standalone Fitzpatrick skin tone modifier support of weston-terminal is 100.0% (0 errors of 5 codepoints tested).
Regional Indicator flag sequence support
Regional Indicator flag sequence support of weston-terminal is 98.9% (3 errors of 262 sequences tested).
Sequence of a Regional Indicator flag sequence, from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\U0001f3f4’ |
So |
2 |
WAVING BLACK FLAG |
|
2 |
‘\U000e0067’ |
Cf |
0 |
TAG LATIN SMALL LETTER G |
|
3 |
‘\U000e0062’ |
Cf |
0 |
TAG LATIN SMALL LETTER B |
|
4 |
‘\U000e0073’ |
Cf |
0 |
TAG LATIN SMALL LETTER S |
|
5 |
‘\U000e0063’ |
Cf |
0 |
TAG LATIN SMALL LETTER C |
|
6 |
‘\U000e0074’ |
Cf |
0 |
TAG LATIN SMALL LETTER T |
|
7 |
‘\U000e007f’ |
Cf |
0 |
CANCEL TAG |
Total codepoints: 7
Shell test using printf(1),
'|'should align in output:$ printf "\xf0\x9f\x8f\xb4\xf3\xa0\x81\xa7\xf3\xa0\x81\xa2\xf3\xa0\x81\xb3\xf3\xa0\x81\xa3\xf3\xa0\x81\xb4\xf3\xa0\x81\xbf|\\n12|\\n" 🏴| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 8.
Graphics Protocol Support
weston-terminal does not report support for any graphics protocols.
Detection Methods:
Sixel and ReGIS: Detected via the Device Attributes (DA1) query
CSI c(\x1b[c). Extension code4indicates Sixel support,3ReGIS.Kitty graphics: Detected by sending a Kitty graphics query and checking for an
OKresponse.iTerm2 inline images: Detected via the iTerm2 capabilities query
OSC 1337 ; Capabilities.
Device Attributes Response:
Language Support
No languages were tested with 100% success.
The following 85 languages are not fully supported:
lang |
n_errors |
n_total |
pct_success |
|---|---|---|---|
3 |
3 |
0.0% |
|
6 |
6 |
0.0% |
|
8 |
8 |
0.0% |
|
8 |
8 |
0.0% |
|
1 |
1 |
0.0% |
|
17 |
17 |
0.0% |
|
3 |
3 |
0.0% |
|
2 |
2 |
0.0% |
|
6 |
6 |
0.0% |
|
4 |
4 |
0.0% |
|
6 |
6 |
0.0% |
|
3 |
3 |
0.0% |
|
6 |
6 |
0.0% |
|
1 |
1 |
0.0% |
|
2 |
2 |
0.0% |
|
160 |
160 |
0.0% |
|
13 |
13 |
0.0% |
|
3 |
3 |
0.0% |
|
1 |
1 |
0.0% |
|
2 |
2 |
0.0% |
|
9 |
9 |
0.0% |
|
1 |
1 |
0.0% |
|
1 |
1 |
0.0% |
|
2 |
2 |
0.0% |
|
2 |
2 |
0.0% |
|
8 |
8 |
0.0% |
|
3 |
3 |
0.0% |
|
8 |
8 |
0.0% |
|
209 |
209 |
0.0% |
|
6 |
6 |
0.0% |
|
3 |
3 |
0.0% |
|
1 |
1 |
0.0% |
|
2 |
2 |
0.0% |
|
4 |
4 |
0.0% |
|
1 |
1 |
0.0% |
|
1 |
1 |
0.0% |
|
3 |
3 |
0.0% |
|
1 |
1 |
0.0% |
|
1 |
1 |
0.0% |
|
24 |
24 |
0.0% |
|
1 |
1 |
0.0% |
|
1 |
1 |
0.0% |
|
2 |
2 |
0.0% |
|
1 |
1 |
0.0% |
|
6 |
6 |
0.0% |
|
16 |
16 |
0.0% |
|
120 |
120 |
0.0% |
|
11 |
11 |
0.0% |
|
5 |
5 |
0.0% |
|
2 |
2 |
0.0% |
|
14 |
14 |
0.0% |
|
48 |
48 |
0.0% |
|
13 |
13 |
0.0% |
|
2 |
2 |
0.0% |
|
1 |
1 |
0.0% |
|
42 |
42 |
0.0% |
|
10 |
10 |
0.0% |
|
10 |
10 |
0.0% |
|
8 |
8 |
0.0% |
|
201 |
208 |
3.4% |
|
22 |
23 |
4.3% |
|
217 |
227 |
4.4% |
|
337 |
354 |
4.8% |
|
67 |
71 |
5.6% |
|
146 |
155 |
5.8% |
|
193 |
206 |
6.3% |
|
61 |
66 |
7.6% |
|
449 |
488 |
8.0% |
|
93 |
103 |
9.7% |
|
95 |
106 |
10.4% |
|
200 |
225 |
11.1% |
|
144 |
164 |
12.2% |
|
192 |
223 |
13.9% |
|
286 |
335 |
14.6% |
|
18 |
22 |
18.2% |
|
294 |
390 |
24.6% |
|
165 |
236 |
30.1% |
|
262 |
382 |
31.4% |
|
224 |
335 |
33.1% |
|
167 |
252 |
33.7% |
|
191 |
290 |
34.1% |
|
99 |
198 |
50.0% |
|
104 |
236 |
55.9% |
|
79 |
237 |
66.7% |
|
26 |
132 |
80.3% |
Aja
Sequence of language Aja from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0254’ |
Ll |
1 |
LATIN SMALL LETTER OPEN O |
|
2 |
‘\u0300’ |
Mn |
0 |
COMBINING GRAVE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xc9\x94\xcc\x80|\\n1|\\n" ɔ̀| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Amarakaeri
Sequence of language Amarakaeri from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘I’ |
Lu |
1 |
LATIN CAPITAL LETTER I |
|
2 |
‘\u0331’ |
Mn |
0 |
COMBINING MACRON BELOW |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "I\xcc\xb1|\\n1|\\n" I̱| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Arabic, Standard
Sequence of language Arabic, Standard from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0627’ |
Lo |
1 |
ARABIC LETTER ALEF |
|
2 |
‘\u064b’ |
Mn |
0 |
ARABIC FATHATAN |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xd8\xa7\xd9\x8b|\\n1|\\n" اً| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Assyrian Neo-Aramaic
Sequence of language Assyrian Neo-Aramaic from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0712’ |
Lo |
1 |
SYRIAC LETTER BETH |
|
2 |
‘\u0742’ |
Mn |
0 |
SYRIAC RUKKAKHA |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xdc\x92\xdd\x82|\\n1|\\n" ܒ݂| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Baatonum
Sequence of language Baatonum from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘n’ |
Ll |
1 |
LATIN SMALL LETTER N |
|
2 |
‘\u0300’ |
Mn |
0 |
COMBINING GRAVE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "n\xcc\x80|\\n1|\\n" ǹ| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Bamun
Sequence of language Bamun from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘E’ |
Lu |
1 |
LATIN CAPITAL LETTER E |
|
2 |
‘\u0301’ |
Mn |
0 |
COMBINING ACUTE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "E\xcc\x81|\\n1|\\n" É| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Belanda Viri
Sequence of language Belanda Viri from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\xe4’ |
Ll |
1 |
LATIN SMALL LETTER A WITH DIAERESIS |
|
2 |
‘\u0301’ |
Mn |
0 |
COMBINING ACUTE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xc3\xa4\xcc\x81|\\n1|\\n" ä́| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Bora
Sequence of language Bora from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0197’ |
Lu |
1 |
LATIN CAPITAL LETTER I WITH STROKE |
|
2 |
‘\u0301’ |
Mn |
0 |
COMBINING ACUTE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xc6\x97\xcc\x81|\\n1|\\n" Ɨ́| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Catalan (2)
Sequence of language Catalan (2) from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘A’ |
Lu |
1 |
LATIN CAPITAL LETTER A |
|
2 |
‘\u0300’ |
Mn |
0 |
COMBINING GRAVE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "A\xcc\x80|\\n1|\\n" À| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Chickasaw
Sequence of language Chickasaw from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘A’ |
Lu |
1 |
LATIN CAPITAL LETTER A |
|
2 |
‘\u0331’ |
Mn |
0 |
COMBINING MACRON BELOW |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "A\xcc\xb1|\\n1|\\n" A̱| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Chinantec, Chiltepec
Sequence of language Chinantec, Chiltepec from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\xe4’ |
Ll |
1 |
LATIN SMALL LETTER A WITH DIAERESIS |
|
2 |
‘\u0331’ |
Mn |
0 |
COMBINING MACRON BELOW |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xc3\xa4\xcc\xb1|\\n1|\\n" ä̱| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Dagaare, Southern
Sequence of language Dagaare, Southern from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘u’ |
Ll |
1 |
LATIN SMALL LETTER U |
|
2 |
‘\u0303’ |
Mn |
0 |
COMBINING TILDE |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "u\xcc\x83|\\n1|\\n" ũ| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Dari
Sequence of language Dari from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0627’ |
Lo |
1 |
ARABIC LETTER ALEF |
|
2 |
‘\u0654’ |
Mn |
0 |
ARABIC HAMZA ABOVE |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xd8\xa7\xd9\x94|\\n1|\\n" أ| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Dendi
Sequence of language Dendi from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0254’ |
Ll |
1 |
LATIN SMALL LETTER OPEN O |
|
2 |
‘\u030c’ |
Mn |
0 |
COMBINING CARON |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xc9\x94\xcc\x8c|\\n1|\\n" ɔ̌| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Dinka, Northeastern
Sequence of language Dinka, Northeastern from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0254’ |
Ll |
1 |
LATIN SMALL LETTER OPEN O |
|
2 |
‘\u0308’ |
Mn |
0 |
COMBINING DIAERESIS |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xc9\x94\xcc\x88|\\n1|\\n" ɔ̈| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Dzongkha
Sequence of language Dzongkha from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0f40’ |
Lo |
1 |
TIBETAN LETTER KA |
|
2 |
‘\u0f74’ |
Mn |
0 |
TIBETAN VOWEL SIGN U |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xbd\x80\xe0\xbd\xb4|\\n1|\\n" ཀུ| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Evenki
Sequence of language Evenki from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0430’ |
Ll |
1 |
CYRILLIC SMALL LETTER A |
|
2 |
‘\u0304’ |
Mn |
0 |
COMBINING MACRON |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xd0\xb0\xcc\x84|\\n1|\\n" а̄| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Farsi, Western
Sequence of language Farsi, Western from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0627’ |
Lo |
1 |
ARABIC LETTER ALEF |
|
2 |
‘\u0655’ |
Mn |
0 |
ARABIC HAMZA BELOW |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xd8\xa7\xd9\x95|\\n1|\\n" إ| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Fon
Sequence of language Fon from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u025b’ |
Ll |
1 |
LATIN SMALL LETTER OPEN E |
|
2 |
‘\u030c’ |
Mn |
0 |
COMBINING CARON |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xc9\x9b\xcc\x8c|\\n1|\\n" ɛ̌| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
French (Welche)
Sequence of language French (Welche) from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘E’ |
Lu |
1 |
LATIN CAPITAL LETTER E |
|
2 |
‘\u0300’ |
Mn |
0 |
COMBINING GRAVE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "E\xcc\x80|\\n1|\\n" È| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Fur
Sequence of language Fur from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘ ‘ |
Zs |
1 |
SPACE |
|
2 |
‘\u0331’ |
Mn |
0 |
COMBINING MACRON BELOW |
|
3 |
‘\u0301’ |
Mn |
0 |
COMBINING ACUTE ACCENT |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf " \xcc\xb1\xcc\x81|\\n1|\\n" ̱́| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 3.
Ga
Sequence of language Ga from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘a’ |
Ll |
1 |
LATIN SMALL LETTER A |
|
2 |
‘\u0303’ |
Mn |
0 |
COMBINING TILDE |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "a\xcc\x83|\\n1|\\n" ã| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Gen
Sequence of language Gen from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u025b’ |
Ll |
1 |
LATIN SMALL LETTER OPEN E |
|
2 |
‘\u0301’ |
Mn |
0 |
COMBINING ACUTE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xc9\x9b\xcc\x81|\\n1|\\n" ɛ́| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Gilyak
Sequence of language Gilyak from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0420’ |
Lu |
1 |
CYRILLIC CAPITAL LETTER ER |
|
2 |
‘\u030c’ |
Mn |
0 |
COMBINING CARON |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xd0\xa0\xcc\x8c|\\n1|\\n" Р̌| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Gumuz
Sequence of language Gumuz from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘-’ |
Pd |
1 |
HYPHEN-MINUS |
|
2 |
‘\u0301’ |
Mn |
0 |
COMBINING ACUTE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "-\xcc\x81|\\n1|\\n" -́| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Kabyle
Sequence of language Kabyle from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘ ‘ |
Zs |
1 |
SPACE |
|
2 |
‘\u0323’ |
Mn |
0 |
COMBINING DOT BELOW |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf " \xcc\xa3|\\n1|\\n" ̣| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Lamnso’
Sequence of language Lamnso’ from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘k’ |
Ll |
1 |
LATIN SMALL LETTER K |
|
2 |
‘\u0300’ |
Mn |
0 |
COMBINING GRAVE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "k\xcc\x80|\\n1|\\n" k̀| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Lingala (tones)
Sequence of language Lingala (tones) from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘I’ |
Lu |
1 |
LATIN CAPITAL LETTER I |
|
2 |
‘\u0301’ |
Mn |
0 |
COMBINING ACUTE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "I\xcc\x81|\\n1|\\n" Í| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Maldivian
Sequence of language Maldivian from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0780’ |
Lo |
1 |
THAANA LETTER HAA |
|
2 |
‘\u07a6’ |
Mn |
0 |
THAANA ABAFILI |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xde\x80\xde\xa6|\\n1|\\n" ހަ| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Maori (2)
Sequence of language Maori (2) from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘A’ |
Lu |
1 |
LATIN CAPITAL LETTER A |
|
2 |
‘\u0304’ |
Mn |
0 |
COMBINING MACRON |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "A\xcc\x84|\\n1|\\n" Ā| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Mazahua Central
Sequence of language Mazahua Central from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘A’ |
Lu |
1 |
LATIN CAPITAL LETTER A |
|
2 |
‘\u0338’ |
Mn |
0 |
COMBINING LONG SOLIDUS OVERLAY |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "A\xcc\xb8|\\n1|\\n" A̸| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Mòoré
Sequence of language Mòoré from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘e’ |
Ll |
1 |
LATIN SMALL LETTER E |
|
2 |
‘\u0303’ |
Mn |
0 |
COMBINING TILDE |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "e\xcc\x83|\\n1|\\n" ẽ| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Nanai
Sequence of language Nanai from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0435’ |
Ll |
1 |
CYRILLIC SMALL LETTER IE |
|
2 |
‘\u0308’ |
Mn |
0 |
COMBINING DIAERESIS |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xd0\xb5\xcc\x88|\\n1|\\n" ё| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Orok
Sequence of language Orok from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u04e9’ |
Ll |
1 |
CYRILLIC SMALL LETTER BARRED O |
|
2 |
‘\u0304’ |
Mn |
0 |
COMBINING MACRON |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xd3\xa9\xcc\x84|\\n1|\\n" ө̄| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Otomi, Mezquital
Sequence of language Otomi, Mezquital from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘U’ |
Lu |
1 |
LATIN CAPITAL LETTER U |
|
2 |
‘\u0331’ |
Mn |
0 |
COMBINING MACRON BELOW |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "U\xcc\xb1|\\n1|\\n" U̱| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Panjabi, Western
Sequence of language Panjabi, Western from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0627’ |
Lo |
1 |
ARABIC LETTER ALEF |
|
2 |
‘\u064f’ |
Mn |
0 |
ARABIC DAMMA |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xd8\xa7\xd9\x8f|\\n1|\\n" اُ| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Pashto, Northern
Sequence of language Pashto, Northern from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0648’ |
Lo |
1 |
ARABIC LETTER WAW |
|
2 |
‘\u064e’ |
Mn |
0 |
ARABIC FATHA |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xd9\x88\xd9\x8e|\\n1|\\n" وَ| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Picard
Sequence of language Picard from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘e’ |
Ll |
1 |
LATIN SMALL LETTER E |
|
2 |
‘\u030a’ |
Mn |
0 |
COMBINING RING ABOVE |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "e\xcc\x8a|\\n1|\\n" e̊| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Pular (Adlam)
Sequence of language Pular (Adlam) from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\U0001e900’ |
Lu |
1 |
ADLAM CAPITAL LETTER ALIF |
|
2 |
‘\U0001e944’ |
Mn |
0 |
ADLAM ALIF LENGTHENER |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xf0\x9e\xa4\x80\xf0\x9e\xa5\x84|\\n1|\\n" 𞤀𞥄| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Secoya
Sequence of language Secoya from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\xeb’ |
Ll |
1 |
LATIN SMALL LETTER E WITH DIAERESIS |
|
2 |
‘\u0331’ |
Mn |
0 |
COMBINING MACRON BELOW |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xc3\xab\xcc\xb1|\\n1|\\n" ë̱| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Seraiki
Sequence of language Seraiki from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u06be’ |
Lo |
1 |
ARABIC LETTER HEH DOACHASHMEE |
|
2 |
‘\u0654’ |
Mn |
0 |
ARABIC HAMZA ABOVE |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xda\xbe\xd9\x94|\\n1|\\n" ھٔ| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Shipibo-Conibo
Sequence of language Shipibo-Conibo from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘S’ |
Lu |
1 |
LATIN CAPITAL LETTER S |
|
2 |
‘\u0308’ |
Mn |
0 |
COMBINING DIAERESIS |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "S\xcc\x88|\\n1|\\n" S̈| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Siona
Sequence of language Siona from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘a’ |
Ll |
1 |
LATIN SMALL LETTER A |
|
2 |
‘\u0308’ |
Mn |
0 |
COMBINING DIAERESIS |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "a\xcc\x88|\\n1|\\n" ä| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
South Azerbaijani
Sequence of language South Azerbaijani from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘I’ |
Lu |
1 |
LATIN CAPITAL LETTER I |
|
2 |
‘\u0307’ |
Mn |
0 |
COMBINING DOT ABOVE |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "I\xcc\x87|\\n1|\\n" İ| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Tagalog (Tagalog)
Sequence of language Tagalog (Tagalog) from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u1704’ |
Lo |
1 |
TAGALOG LETTER GA |
|
2 |
‘\u1714’ |
Mn |
0 |
TAGALOG SIGN VIRAMA |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe1\x9c\x84\xe1\x9c\x94|\\n1|\\n" ᜄ᜔| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Tai Dam
Sequence of language Tai Dam from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\uaa80’ |
Lo |
1 |
TAI VIET LETTER LOW KO |
|
2 |
‘\uaab0’ |
Mn |
0 |
TAI VIET MAI KANG |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xea\xaa\x80\xea\xaa\xb0|\\n1|\\n" ꪀꪰ| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Tamang, Eastern
Sequence of language Tamang, Eastern from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
|
2 |
‘\u094d’ |
Mn |
0 |
DEVANAGARI SIGN VIRAMA |
|
3 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
|
4 |
‘\u094b’ |
Mc |
0 |
DEVANAGARI VOWEL SIGN O |
Total codepoints: 4
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa4\x95\xe0\xa5\x8d\xe0\xa4\x95\xe0\xa5\x8b|\\n12|\\n" क्को| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 4.
Tamazight, Central Atlas
Sequence of language Tamazight, Central Atlas from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘H’ |
Lu |
1 |
LATIN CAPITAL LETTER H |
|
2 |
‘\u0323’ |
Mn |
0 |
COMBINING DOT BELOW |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "H\xcc\xa3|\\n1|\\n" Ḥ| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Tem
Sequence of language Tem from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0269’ |
Ll |
1 |
LATIN SMALL LETTER IOTA |
|
2 |
‘\u0301’ |
Mn |
0 |
COMBINING ACUTE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xc9\xa9\xcc\x81|\\n1|\\n" ɩ́| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Thai (2)
Sequence of language Thai (2) from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0e22’ |
Lo |
1 |
THAI CHARACTER YO YAK |
|
2 |
‘\u0e48’ |
Mn |
0 |
THAI CHARACTER MAI EK |
|
3 |
‘\u0e33’ |
Lo |
1 |
THAI CHARACTER SARA AM |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xb8\xa2\xe0\xb9\x88\xe0\xb8\xb3|\\n12|\\n" ย่ำ| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 3.
Tibetan, Central
Sequence of language Tibetan, Central from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘ ‘ |
Zs |
1 |
SPACE |
|
2 |
‘\u0f7c’ |
Mn |
0 |
TIBETAN VOWEL SIGN O |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf " \xe0\xbd\xbc|\\n1|\\n" ོ| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Ticuna
Sequence of language Ticuna from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘c’ |
Ll |
1 |
LATIN SMALL LETTER C |
|
2 |
‘\u0331’ |
Mn |
0 |
COMBINING MACRON BELOW |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "c\xcc\xb1|\\n1|\\n" c̱| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Uduk
Sequence of language Uduk from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘p’ |
Ll |
1 |
LATIN SMALL LETTER P |
|
2 |
‘\u0331’ |
Mn |
0 |
COMBINING MACRON BELOW |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "p\xcc\xb1|\\n1|\\n" p̱| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Urdu (2)
Sequence of language Urdu (2) from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u06a9’ |
Lo |
1 |
ARABIC LETTER KEHEH |
|
2 |
‘\u064f’ |
Mn |
0 |
ARABIC DAMMA |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xda\xa9\xd9\x8f|\\n1|\\n" کُ| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Vietnamese
Sequence of language Vietnamese from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘Y’ |
Lu |
1 |
LATIN CAPITAL LETTER Y |
|
2 |
‘\u0301’ |
Mn |
0 |
COMBINING ACUTE ACCENT |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "Y\xcc\x81|\\n1|\\n" Ý| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Yaneshaʼ
Sequence of language Yaneshaʼ from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘ ‘ |
Zs |
1 |
SPACE |
|
2 |
‘\u0303’ |
Mn |
0 |
COMBINING TILDE |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf " \xcc\x83|\\n1|\\n" ̃| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Yiddish, Eastern
Sequence of language Yiddish, Eastern from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u05d0’ |
Lo |
1 |
HEBREW LETTER ALEF |
|
2 |
‘\u05b7’ |
Mn |
0 |
HEBREW POINT PATAH |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xd7\x90\xd6\xb7|\\n1|\\n" אַ| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Yoruba
Sequence of language Yoruba from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘n’ |
Ll |
1 |
LATIN SMALL LETTER N |
|
2 |
‘\u0304’ |
Mn |
0 |
COMBINING MACRON |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "n\xcc\x84|\\n1|\\n" n̄| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Mon
Sequence of language Mon from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u1000’ |
Lo |
1 |
MYANMAR LETTER KA |
|
2 |
‘\u1031’ |
Mc |
0 |
MYANMAR VOWEL SIGN E |
|
3 |
‘\u102f’ |
Mn |
0 |
MYANMAR VOWEL SIGN U |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe1\x80\x80\xe1\x80\xb1\xe1\x80\xaf|\\n12|\\n" ကေု| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 3.
Urdu
Sequence of language Urdu from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0628’ |
Lo |
1 |
ARABIC LETTER BEH |
|
2 |
‘\u064e’ |
Mn |
0 |
ARABIC FATHA |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xd8\xa8\xd9\x8e|\\n1|\\n" بَ| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Lao
Sequence of language Lao from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0e81’ |
Lo |
1 |
LAO LETTER KO |
|
2 |
‘\u0eb1’ |
Mn |
0 |
LAO VOWEL SIGN MAI KAN |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xba\x81\xe0\xba\xb1|\\n1|\\n" ກັ| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Khün
Sequence of language Khün from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u1a20’ |
Lo |
1 |
TAI THAM LETTER HIGH KA |
|
2 |
‘\u1a60’ |
Mn |
0 |
TAI THAM SIGN SAKOT |
|
3 |
‘\u1a20’ |
Lo |
1 |
TAI THAM LETTER HIGH KA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe1\xa8\xa0\xe1\xa9\xa0\xe1\xa8\xa0|\\n12|\\n" ᨠ᩠ᨠ| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 3.
Nepali
Sequence of language Nepali from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
|
2 |
‘\u094d’ |
Mn |
0 |
DEVANAGARI SIGN VIRAMA |
|
3 |
‘\u091b’ |
Lo |
1 |
DEVANAGARI LETTER CHA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa4\x95\xe0\xa5\x8d\xe0\xa4\x9b|\\n12|\\n" क्छ| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 3.
Sanskrit
Sequence of language Sanskrit from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
|
2 |
‘\u094d’ |
Mn |
0 |
DEVANAGARI SIGN VIRAMA |
|
3 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
|
4 |
‘\u093e’ |
Mc |
0 |
DEVANAGARI VOWEL SIGN AA |
Total codepoints: 4
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa4\x95\xe0\xa5\x8d\xe0\xa4\x95\xe0\xa4\xbe|\\n12|\\n" क्का| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 4.
Thai
Sequence of language Thai from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0e15’ |
Lo |
1 |
THAI CHARACTER TO TAO |
|
2 |
‘\u0e48’ |
Mn |
0 |
THAI CHARACTER MAI EK |
|
3 |
‘\u0e33’ |
Lo |
1 |
THAI CHARACTER SARA AM |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xb8\x95\xe0\xb9\x88\xe0\xb8\xb3|\\n12|\\n" ต่ำ| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 3.
Maithili
Sequence of language Maithili from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
|
2 |
‘\u093f’ |
Mc |
0 |
DEVANAGARI VOWEL SIGN I |
|
3 |
‘\u0902’ |
Mn |
0 |
DEVANAGARI SIGN ANUSVARA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa4\x95\xe0\xa4\xbf\xe0\xa4\x82|\\n12|\\n" किं| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 3.
Javanese (Javanese)
Sequence of language Javanese (Javanese) from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\ua98f’ |
Lo |
1 |
JAVANESE LETTER KA |
|
2 |
‘\ua9ba’ |
Mc |
0 |
JAVANESE VOWEL SIGN TALING |
|
3 |
‘\ua9b4’ |
Mc |
0 |
JAVANESE VOWEL SIGN TARUNG |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xea\xa6\x8f\xea\xa6\xba\xea\xa6\xb4|\\n12|\\n" ꦏꦺꦴ| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 3.
Marathi
Sequence of language Marathi from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
|
2 |
‘\u094d’ |
Mn |
0 |
DEVANAGARI SIGN VIRAMA |
|
3 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
|
4 |
‘\u093e’ |
Mc |
0 |
DEVANAGARI VOWEL SIGN AA |
|
5 |
‘\u0902’ |
Mn |
0 |
DEVANAGARI SIGN ANUSVARA |
Total codepoints: 5
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa4\x95\xe0\xa5\x8d\xe0\xa4\x95\xe0\xa4\xbe\xe0\xa4\x82|\\n12|\\n" क्कां| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 5.
Shan
Sequence of language Shan from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u1004’ |
Lo |
1 |
MYANMAR LETTER NGA |
|
2 |
‘\u102d’ |
Mn |
0 |
MYANMAR VOWEL SIGN I |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe1\x80\x84\xe1\x80\xad|\\n1|\\n" ငိ| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
Chakma
Sequence of language Chakma from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\U00011103’ |
Lo |
1 |
CHAKMA LETTER AA |
|
2 |
‘\U0001112c’ |
Mc |
0 |
CHAKMA VOWEL SIGN E |
|
3 |
‘\U0001112d’ |
Mn |
0 |
CHAKMA VOWEL SIGN AI |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xf0\x91\x84\x83\xf0\x91\x84\xac\xf0\x91\x84\xad|\\n12|\\n" 𑄃𑄬𑄭| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 3.
Hindi
Sequence of language Hindi from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
|
2 |
‘\u093e’ |
Mc |
0 |
DEVANAGARI VOWEL SIGN AA |
|
3 |
‘\u0902’ |
Mn |
0 |
DEVANAGARI SIGN ANUSVARA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa4\x95\xe0\xa4\xbe\xe0\xa4\x82|\\n12|\\n" कां| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 3.
Burmese
Sequence of language Burmese from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u1000’ |
Lo |
1 |
MYANMAR LETTER KA |
|
2 |
‘\u1039’ |
Mn |
0 |
MYANMAR SIGN VIRAMA |
|
3 |
‘\u1001’ |
Lo |
1 |
MYANMAR LETTER KHA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe1\x80\x80\xe1\x80\xb9\xe1\x80\x81|\\n12|\\n" က္ခ| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 3.
Telugu
Sequence of language Telugu from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0c15’ |
Lo |
1 |
TELUGU LETTER KA |
|
2 |
‘\u0c3e’ |
Mn |
0 |
TELUGU VOWEL SIGN AA |
|
3 |
‘\u0c02’ |
Mc |
0 |
TELUGU SIGN ANUSVARA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xb0\x95\xe0\xb0\xbe\xe0\xb0\x82|\\n12|\\n" కాం| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 3.
Magahi
Sequence of language Magahi from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
|
2 |
‘\u094d’ |
Mn |
0 |
DEVANAGARI SIGN VIRAMA |
|
3 |
‘\u0930’ |
Lo |
1 |
DEVANAGARI LETTER RA |
|
4 |
‘\u0942’ |
Mn |
0 |
DEVANAGARI VOWEL SIGN UU |
Total codepoints: 4
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa4\x95\xe0\xa5\x8d\xe0\xa4\xb0\xe0\xa5\x82|\\n12|\\n" क्रू| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 4.
Khmer, Central
Sequence of language Khmer, Central from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u1780’ |
Lo |
1 |
KHMER LETTER KA |
|
2 |
‘\u17d2’ |
Mn |
0 |
KHMER SIGN COENG |
|
3 |
‘\u1781’ |
Lo |
1 |
KHMER LETTER KHA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe1\x9e\x80\xe1\x9f\x92\xe1\x9e\x81|\\n12|\\n" ក្ខ| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 3.
Panjabi, Eastern
Sequence of language Panjabi, Eastern from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0a15’ |
Lo |
1 |
GURMUKHI LETTER KA |
|
2 |
‘\u0a3e’ |
Mc |
0 |
GURMUKHI VOWEL SIGN AA |
|
3 |
‘\u0a02’ |
Mn |
0 |
GURMUKHI SIGN BINDI |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa8\x95\xe0\xa8\xbe\xe0\xa8\x82|\\n12|\\n" ਕਾਂ| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 3.
Malayalam
Sequence of language Malayalam from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0d15’ |
Lo |
1 |
MALAYALAM LETTER KA |
|
2 |
‘\u0d4d’ |
Mn |
0 |
MALAYALAM SIGN VIRAMA |
|
3 |
‘\u0d15’ |
Lo |
1 |
MALAYALAM LETTER KA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xb4\x95\xe0\xb5\x8d\xe0\xb4\x95|\\n12|\\n" ക്ക| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 3.
Bengali
Sequence of language Bengali from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0995’ |
Lo |
1 |
BENGALI LETTER KA |
|
2 |
‘\u09be’ |
Mc |
0 |
BENGALI VOWEL SIGN AA |
|
3 |
‘\u200c’ |
Cf |
0 |
ZERO WIDTH NON-JOINER |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa6\x95\xe0\xa6\xbe\xe2\x80\x8c|\\n12|\\n" কা| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 3.
Bhojpuri
Sequence of language Bhojpuri from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
|
2 |
‘\u094d’ |
Mn |
0 |
DEVANAGARI SIGN VIRAMA |
|
3 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa4\x95\xe0\xa5\x8d\xe0\xa4\x95|\\n12|\\n" क्क| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 3.
Gujarati
Sequence of language Gujarati from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0a95’ |
Lo |
1 |
GUJARATI LETTER KA |
|
2 |
‘\u0abe’ |
Mc |
0 |
GUJARATI VOWEL SIGN AA |
|
3 |
‘\u0a82’ |
Mn |
0 |
GUJARATI SIGN ANUSVARA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xaa\x95\xe0\xaa\xbe\xe0\xaa\x82|\\n12|\\n" કાં| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 3.
Sinhala
Sequence of language Sinhala from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0daf’ |
Lo |
1 |
SINHALA LETTER ALPAPRAANA DAYANNA |
|
2 |
‘\u0dd2’ |
Mn |
0 |
SINHALA VOWEL SIGN KETTI IS-PILLA |
|
3 |
‘\u0d82’ |
Mc |
0 |
SINHALA SIGN ANUSVARAYA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xb6\xaf\xe0\xb7\x92\xe0\xb6\x82|\\n12|\\n" දිං| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 3.
Kannada
Sequence of language Kannada from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0c95’ |
Lo |
1 |
KANNADA LETTER KA |
|
2 |
‘\u0cbe’ |
Mc |
0 |
KANNADA VOWEL SIGN AA |
|
3 |
‘\u0c82’ |
Mc |
0 |
KANNADA SIGN ANUSVARA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xb2\x95\xe0\xb2\xbe\xe0\xb2\x82|\\n12|\\n" ಕಾಂ| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 3.
Sanskrit (Grantha)
Sequence of language Sanskrit (Grantha) from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\U00011315’ |
Lo |
1 |
GRANTHA LETTER KA |
|
2 |
‘\U0001133e’ |
Mc |
0 |
GRANTHA VOWEL SIGN AA |
|
3 |
‘\U00011302’ |
Mc |
0 |
GRANTHA SIGN ANUSVARA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xf0\x91\x8c\x95\xf0\x91\x8c\xbe\xf0\x91\x8c\x82|\\n12|\\n" 𑌕𑌾𑌂| 12|
python wcwidth.wcswidth() measures width 2, while weston-terminal measures width 3.
Tamil
Sequence of language Tamil from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0b95’ |
Lo |
1 |
TAMIL LETTER KA |
|
2 |
‘\u0bc0’ |
Mn |
0 |
TAMIL VOWEL SIGN II |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xae\x95\xe0\xaf\x80|\\n1|\\n" கீ| 1|
python wcwidth.wcswidth() measures width 1, while weston-terminal measures width 2.
DEC Private Modes Support
This Terminal does not appear capable of reporting about any DEC Private modes.
Kitty Keyboard Protocol
weston-terminal does not support the Kitty keyboard protocol.
XTGETTCAP (Terminfo Capabilities)
weston-terminal does not support the XTGETTCAP sequence.
Text Sizing Protocol (OSC 66)
weston-terminal does not support the Text Sizing protocol.
Truecolor Support
weston-terminal does not support 24-bit truecolor. (Reports 8 colors.)
XTGETTCAP (RGB capability): no
DECRQSS (truecolor probe): no
COLORTERM: xterm
OSC 52 Clipboard Support
weston-terminal does not advertise OSC 52 clipboard support via DA1 extension 52 or XTGETTCAP Ms.
DA1 extension 52: no
XTGETTCAP Ms: no
Terminal Identification
weston-terminal could not be identified via XTVERSION, XTGETTCAP TN, ENQ, or TERM_PROGRAM.
XTVERSION: no
XTGETTCAP TN: no
ENQ: no
TERM_PROGRAM: no
TERM: no (xterm)
Reproduction
To reproduce these results for weston-terminal, install and run ucs-detect with the following commands:
uvx ucs-detect --rerun data/westonterminal.yaml
Test Performance
The test suite completed in 6.01 seconds (6s).
Mean CPU: 5.3%
Mean RSS: 22.3 MB
Total time: 6.0s
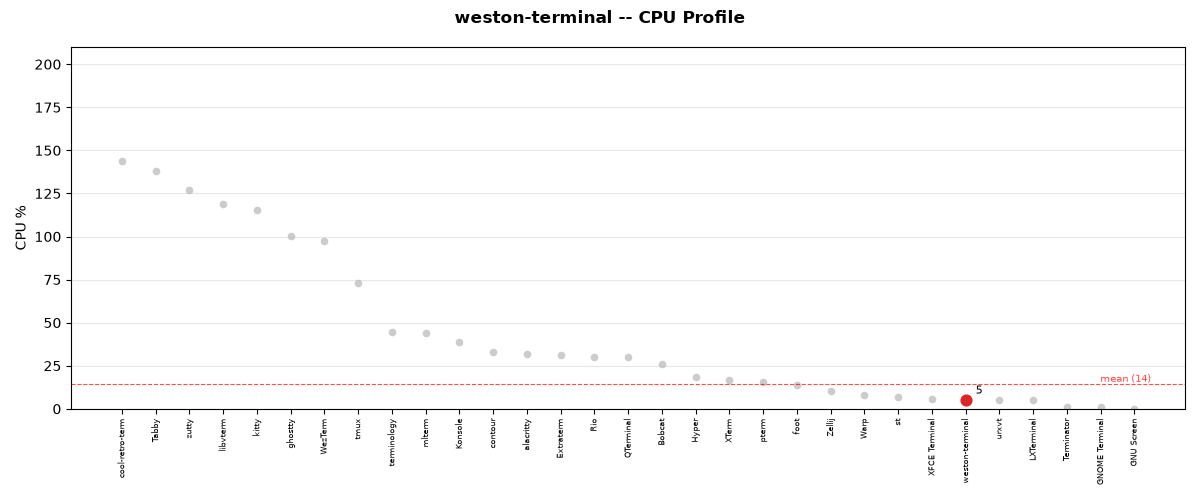
CPU usage during test execution for weston-terminal.
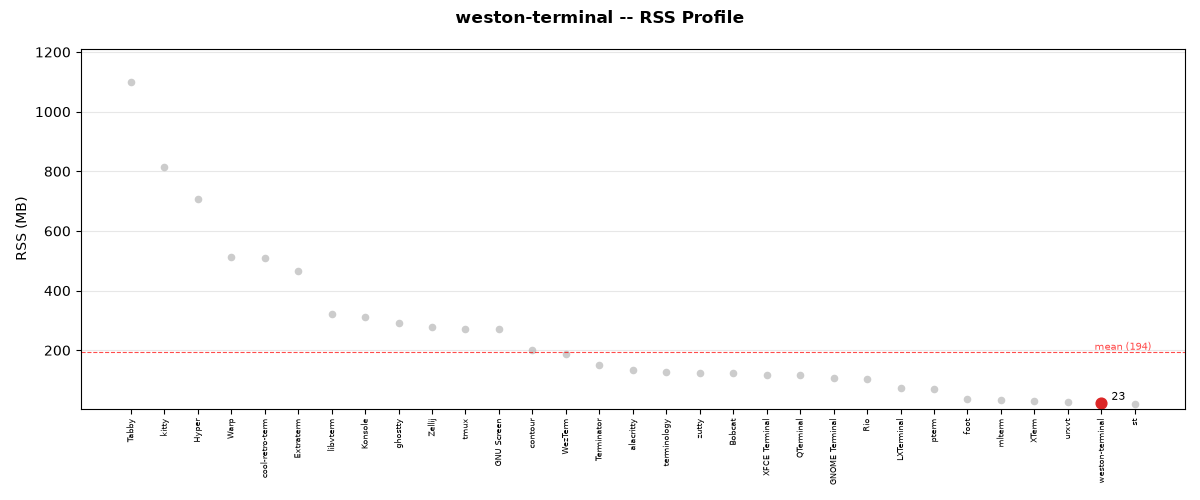
RSS memory usage during test execution for weston-terminal.
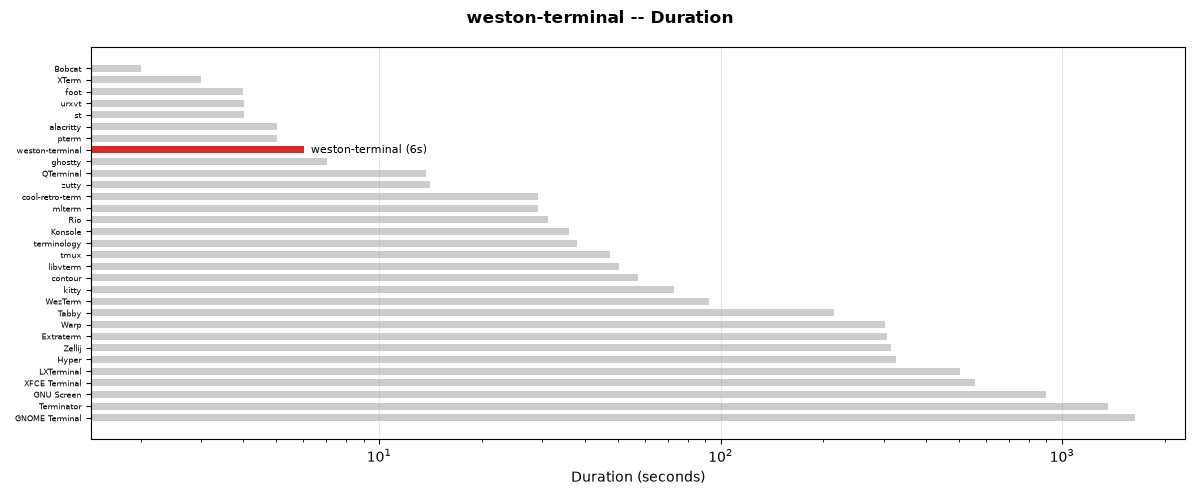
Test duration for weston-terminal compared to all other terminals.
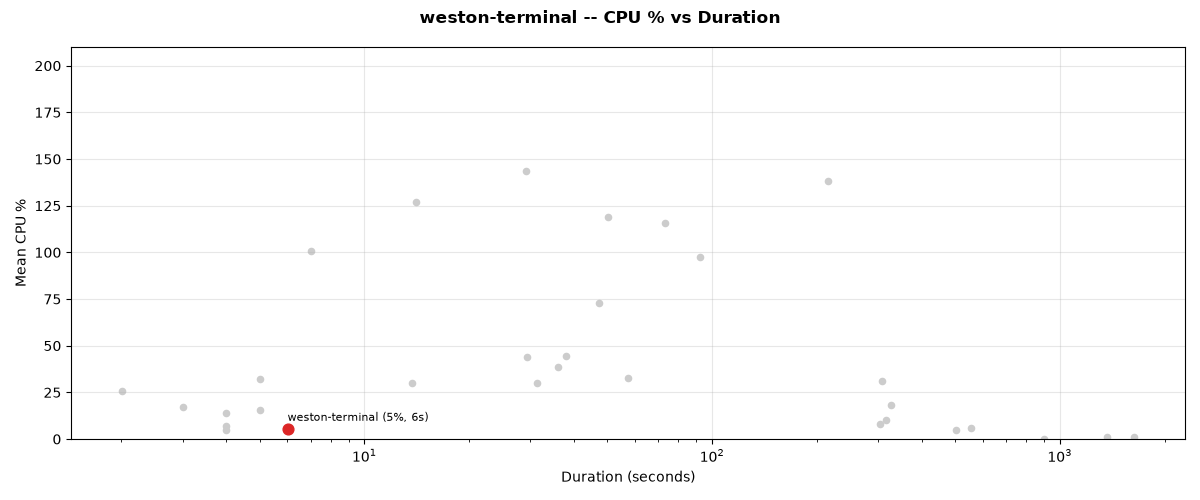
CPU % vs duration trade-off for weston-terminal.