WezTerm
Tested Software version 20240203-110809-5046fc22 on Linux. The homepage URL of this terminal is https://wezfurlong.org/wezterm/. Full results available at ucs-detect repository path data/wezterm.yaml.
Score Breakdown
Detailed breakdown of how scores are calculated for WezTerm:
# |
Score Type |
Raw Score |
Final Scaled Score |
|---|---|---|---|
1 |
54.94% |
36.3% |
|
2 |
92.51% |
92.5% |
|
3 |
100.00% |
100.0% |
|
4 |
86.83% |
86.8% |
|
5 |
50.00% |
50.0% |
|
6 |
0.00% |
(excluded) |
|
7 |
0.00% |
0.0% |
|
8 |
100.00% |
100.0% |
|
9 |
100.00% |
100.0% |
|
10 |
62.50% |
66.7% |
|
11 |
100% |
100.0% |
|
12 |
27.5% |
27.5% |
Score Comparison Plot:
The following plot shows how this terminal’s scores compare to all other terminals tested.

Scaled scores comparison across all metrics (normalized 0-100%)
Final Scaled Score Calculation:
Raw Final Score: 66.61% (weighted average: WIDE + NARROW + ZWJ + LANG + VS16 + 0.33 * SRI + 0.33 * SFZ + RI + CAP + 0.5 * GFX + 0.5 * RSC) the categorized ‘average’ absolute support level of this terminal.
Note
RSC (Resources) is a composite CPU, memory, and runtime score. RSC is weighted at 0.5 (half as powerful as other metrics). FEAT (Features) is the fraction of notable features supported. GFX (Graphics) scores 100% for modern protocols (iTerm2, Kitty), 50% for legacy only (Sixel, ReGIS), 0% for none.
Final Scaled Score: 53.5% (normalized across all terminals tested). Final Scaled scores are normalized (0-100%) relative to all terminals tested
WIDE Score Details:
Wide character support calculation:
Total successful codepoints: 278
Total codepoints tested: 506
Formula: 278 / 506
Result: 54.94%
NARROW Score Details:
Narrow character support calculation:
Total successful codepoints: 173
Total codepoints tested: 187
Formula: 173 / 187
Result: 92.51%
ZWJ Score Details:
Emoji ZWJ (Zero-Width Joiner) support calculation:
Total successful sequences: 1445
Total sequences tested: 1445
Formula: 1445 / 1445
Result: 100.00%
VS16 Score Details:
Variation Selector-16 support calculation:
Errors: 213 of 426 codepoints tested
Success rate: 50.0%
Formula: 50.0 / 100
Result: 50.00%
VS15 Score Details (excluded from final score):
Variation Selector-15 support calculation:
Errors: 158 of 158 codepoints tested
Success rate: 0.0%
Formula: 0.0 / 100
Result: 0.00%
SRI Score Details:
Standalone Regional Indicator support calculation:
Total successful codepoints: 0
Total codepoints tested: 26
Formula: 0 / 26
Result: 0.00%
SFZ Score Details:
Standalone Fitzpatrick skin tone modifier support calculation:
Total successful codepoints: 5
Total codepoints tested: 5
Formula: 5 / 5
Result: 100.00%
RI Score Details:
Regional Indicator flag sequence support calculation:
Total successful sequences: 262
Total sequences tested: 262
Formula: 262 / 262
Result: 100.00%
Features Score Details:
Notable terminal features (10.0 / 16):
Kitty Keyboard: no
XTGETTCAP (Full): yes
OSC 52 Clipboard: yes
Truecolor Detection: yes
Raw score: 62.50%
Graphics Score Details:
Graphics protocol support (100%):
Sixel: yes
ReGIS: no
iTerm2: no
Kitty: yes
Scoring: 100% for modern (iTerm2/Kitty), 50% for legacy only (Sixel/ReGIS), 0% for none
Resource Score Details:
Duration: 92.2s
Mean CPU: 97.6%
Mean RSS: 178.5 MB
Resources Score: 27/100
Note: log-scale composite cost = log(CPU+1) + log(RSS+1) + log(time+1)
Scaled result: 27.5%
LANG Score Details (Geometric Mean):
Geometric mean calculation:
Formula: (p₁ × p₂ × … × pₙ)^(1/n) where n = 85 languages
About geometric mean
Result: 86.83%
Wide character support
Wide character support of WezTerm is 54.9% (228 errors of 506 codepoints tested).
Sequence of a WIDE character, from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\U0001d31d’ |
So |
2 |
TETRAGRAM FOR JOY |
Total codepoints: 1
Shell test using printf(1),
'|'should align in output:$ printf "\xf0\x9d\x8c\x9d|\\n12|\\n" 𝌝| 12|
See Line 42264 of ucs_wide.txt for this sequence in the example file.
Screenshot:
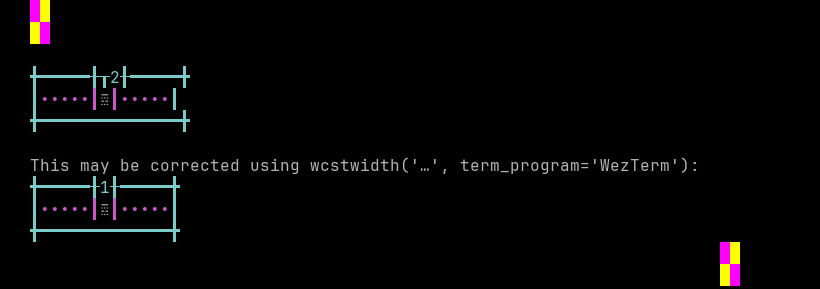
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 1.
Narrow character support
Narrow character support of WezTerm is 92.5% (14 errors of 187 codepoints tested).
Sequence of a NARROW character, from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u06dd’ |
Cf |
1 |
ARABIC END OF AYAH |
Total codepoints: 1
Shell test using printf(1),
'|'should align in output:$ printf "\xdb\x9d|\\n1|\\n" | 1|
python wcwidth.wcswidth() measures width 1, while WezTerm measures width 0.
Emoji ZWJ support
Compatibility of WezTerm with the Unicode Emoji ZWJ sequence table is 100.0% (0 errors of 1445 sequences tested).
Variation Selector-16 support
Emoji VS-16 results for WezTerm is 213 errors out of 426 total codepoints tested, 50.0% success. Sequence of a NARROW Emoji made WIDE by Variation Selector-16, from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u2733’ |
So |
1 |
EIGHT SPOKED ASTERISK |
|
2 |
‘\ufe0f’ |
Mn |
0 |
VARIATION SELECTOR-16 |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe2\x9c\xb3\xef\xb8\x8f|\\n12|\\n" ✳️| 12|
Screenshot:
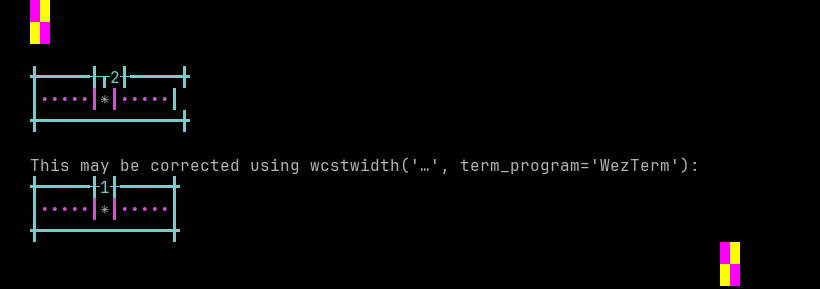
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 1.
Variation Selector-15 support
Emoji VS-15 results for WezTerm is 158 errors out of 158 total codepoints tested, 0.0% success. Sequence of a WIDE Emoji made NARROW by Variation Selector-15, from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\U0001f3ae’ |
So |
2 |
VIDEO GAME |
|
2 |
‘\ufe0e’ |
Mn |
0 |
VARIATION SELECTOR-15 |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xf0\x9f\x8e\xae\xef\xb8\x8e|\\n1|\\n" 🎮︎| 1|
Screenshot:
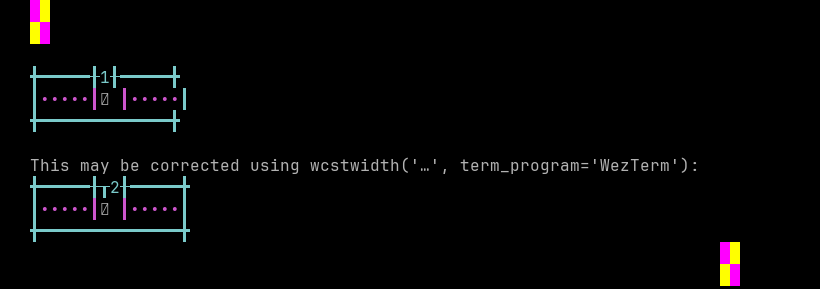
python wcwidth.wcswidth() measures width 1, while WezTerm measures width 2.
Standalone Regional Indicator support
Standalone Regional Indicator support of WezTerm is 0.0% (26 errors of 26 codepoints tested).
Sequence of a standalone Regional Indicator, from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\U0001f1f3’ |
So |
2 |
REGIONAL INDICATOR SYMBOL LETTER N |
Total codepoints: 1
Shell test using printf(1),
'|'should align in output:$ printf "\xf0\x9f\x87\xb3|\\n12|\\n" 🇳| 12|
Screenshot:
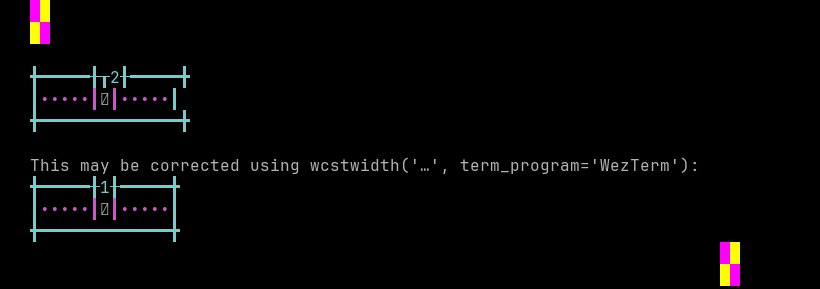
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 1.
Standalone Fitzpatrick modifier support
Standalone Fitzpatrick skin tone modifier support of WezTerm is 100.0% (0 errors of 5 codepoints tested).
Regional Indicator flag sequence support
Regional Indicator flag sequence support of WezTerm is 100.0% (0 errors of 262 sequences tested).
Graphics Protocol Support
WezTerm supports the following graphics protocols: Sixel, Kitty graphics.
Detection Methods:
Sixel and ReGIS: Detected via the Device Attributes (DA1) query
CSI c(\x1b[c). Extension code4indicates Sixel support,3ReGIS.Kitty graphics: Detected by sending a Kitty graphics query and checking for an
OKresponse.iTerm2 inline images: Detected via the iTerm2 capabilities query
OSC 1337 ; Capabilities.
Device Attributes Response:
Language Support
The following 61 languages were tested with 100% success:
Aja, Amarakaeri, Arabic, Standard, Assyrian Neo-Aramaic, Baatonum, Bamun, Belanda Viri, Bora, Catalan (2), Chickasaw, Chinantec, Chiltepec, Dagaare, Southern, Dari, Dendi, Dinka, Northeastern, Dzongkha, Evenki, Farsi, Western, Fon, French (Welche), Fur, Ga, Gen, Gilyak, Gumuz, Kabyle, Lamnso’, Lao, Lingala (tones), Maldivian, Maori (2), Mazahua Central, Mòoré, Nanai, Navajo, Orok, Otomi, Mezquital, Panjabi, Western, Pashto, Northern, Picard, Pular (Adlam), Secoya, Seraiki, Shipibo-Conibo, Siona, South Azerbaijani, Tagalog (Tagalog), Tai Dam, Tamang, Eastern, Tamazight, Central Atlas, Tem, Thai, Thai (2), Tibetan, Central, Ticuna, Uduk, Urdu (2), Vietnamese, Yaneshaʼ, Yiddish, Eastern, Yoruba.
The following 24 languages are not fully supported:
lang |
n_errors |
n_total |
pct_success |
|---|---|---|---|
197 |
237 |
16.9% |
|
106 |
132 |
19.7% |
|
157 |
236 |
33.5% |
|
101 |
198 |
49.0% |
|
103 |
236 |
56.4% |
|
145 |
335 |
56.7% |
|
108 |
252 |
57.1% |
|
162 |
382 |
57.6% |
|
120 |
290 |
58.6% |
|
8 |
22 |
63.6% |
|
76 |
223 |
65.9% |
|
116 |
390 |
70.3% |
|
44 |
155 |
71.6% |
|
29 |
103 |
71.8% |
|
45 |
164 |
72.6% |
|
93 |
354 |
73.7% |
|
86 |
335 |
74.3% |
|
15 |
66 |
77.3% |
|
45 |
208 |
78.4% |
|
86 |
488 |
82.4% |
|
12 |
71 |
83.1% |
|
34 |
225 |
84.9% |
|
11 |
106 |
89.6% |
|
1 |
23 |
95.7% |
Sanskrit (Grantha)
Sequence of language Sanskrit (Grantha) from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\U00011305’ |
Lo |
1 |
GRANTHA LETTER A |
|
2 |
‘\U00011302’ |
Mc |
0 |
GRANTHA SIGN ANUSVARA |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xf0\x91\x8c\x85\xf0\x91\x8c\x82|\\n12|\\n" 𑌅𑌂| 12|
Screenshot:
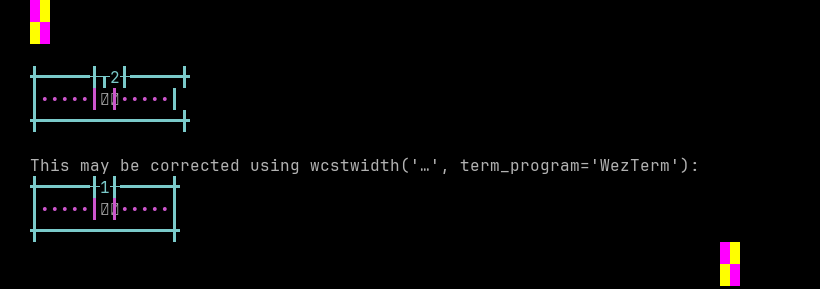
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 1.
Tamil
Sequence of language Tamil from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0b95’ |
Lo |
1 |
TAMIL LETTER KA |
|
2 |
‘\u0bbe’ |
Mc |
0 |
TAMIL VOWEL SIGN AA |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xae\x95\xe0\xae\xbe|\\n12|\\n" கா| 12|
Screenshot:
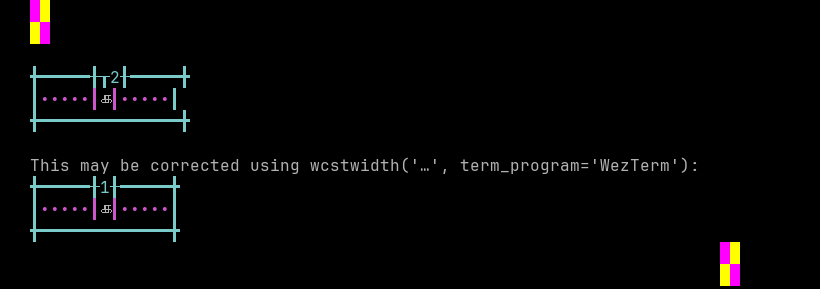
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 1.
Kannada
Sequence of language Kannada from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0c85’ |
Lo |
1 |
KANNADA LETTER A |
|
2 |
‘\u0c82’ |
Mc |
0 |
KANNADA SIGN ANUSVARA |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xb2\x85\xe0\xb2\x82|\\n12|\\n" ಅಂ| 12|
Screenshot:
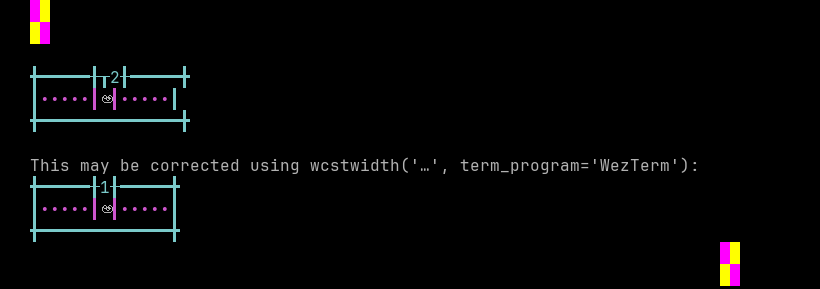
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 1.
Sinhala
Sequence of language Sinhala from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0d9a’ |
Lo |
1 |
SINHALA LETTER ALPAPRAANA KAYANNA |
|
2 |
‘\u0dcf’ |
Mc |
0 |
SINHALA VOWEL SIGN AELA-PILLA |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xb6\x9a\xe0\xb7\x8f|\\n12|\\n" කා| 12|
Screenshot:
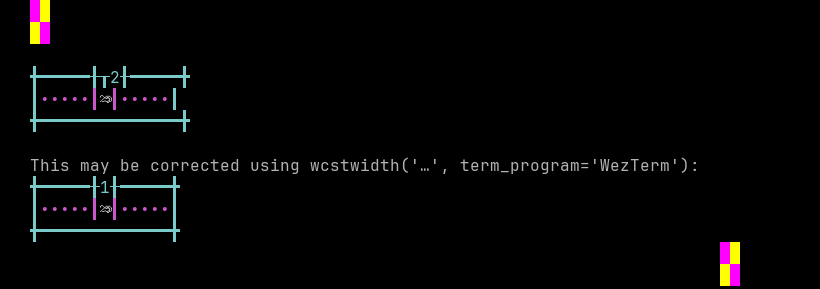
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 1.
Panjabi, Eastern
Sequence of language Panjabi, Eastern from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0a15’ |
Lo |
1 |
GURMUKHI LETTER KA |
|
2 |
‘\u0a3e’ |
Mc |
0 |
GURMUKHI VOWEL SIGN AA |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa8\x95\xe0\xa8\xbe|\\n12|\\n" ਕਾ| 12|
Screenshot:
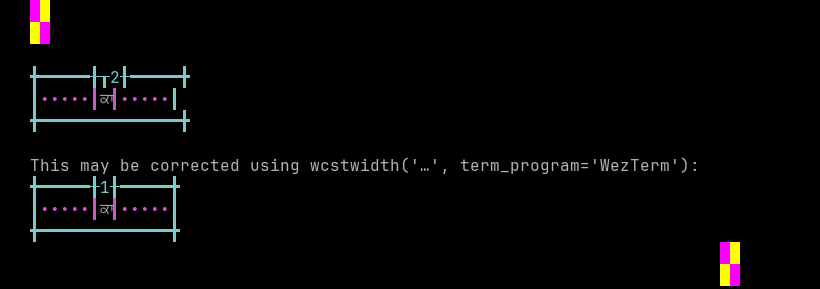
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 1.
Bengali
Sequence of language Bengali from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0985’ |
Lo |
1 |
BENGALI LETTER A |
|
2 |
‘\u0982’ |
Mc |
0 |
BENGALI SIGN ANUSVARA |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa6\x85\xe0\xa6\x82|\\n12|\\n" অং| 12|
Screenshot:
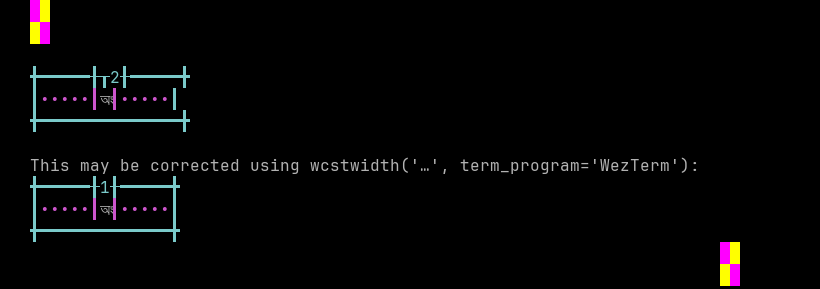
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 1.
Bhojpuri
Sequence of language Bhojpuri from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
|
2 |
‘\u093e’ |
Mc |
0 |
DEVANAGARI VOWEL SIGN AA |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa4\x95\xe0\xa4\xbe|\\n12|\\n" का| 12|
Screenshot:
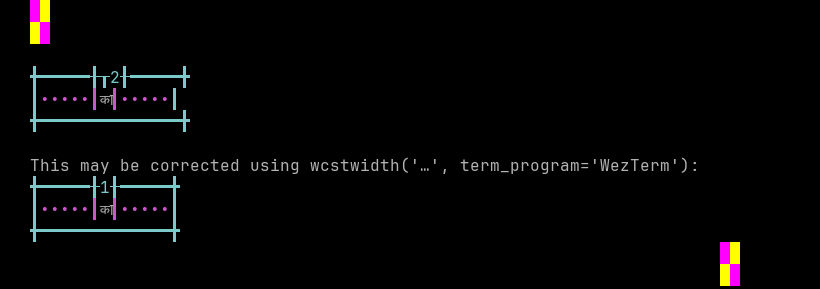
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 1.
Malayalam
Sequence of language Malayalam from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0d05’ |
Lo |
1 |
MALAYALAM LETTER A |
|
2 |
‘\u0d02’ |
Mc |
0 |
MALAYALAM SIGN ANUSVARA |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xb4\x85\xe0\xb4\x82|\\n12|\\n" അം| 12|
Screenshot:
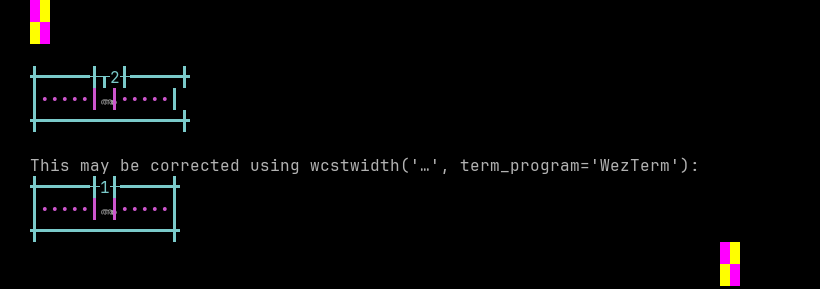
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 1.
Gujarati
Sequence of language Gujarati from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0a95’ |
Lo |
1 |
GUJARATI LETTER KA |
|
2 |
‘\u0a83’ |
Mc |
0 |
GUJARATI SIGN VISARGA |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xaa\x95\xe0\xaa\x83|\\n12|\\n" કઃ| 12|
Screenshot:
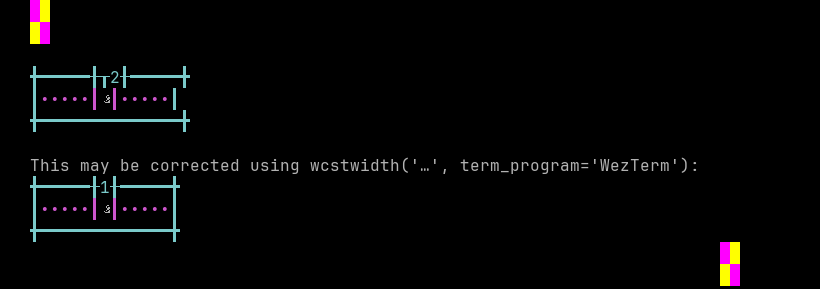
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 1.
Magahi
Sequence of language Magahi from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
|
2 |
‘\u094d’ |
Mn |
0 |
DEVANAGARI SIGN VIRAMA |
|
3 |
‘\u0937’ |
Lo |
1 |
DEVANAGARI LETTER SSA |
|
4 |
‘\u094d’ |
Mn |
0 |
DEVANAGARI SIGN VIRAMA |
|
5 |
‘\u0923’ |
Lo |
1 |
DEVANAGARI LETTER NNA |
Total codepoints: 5
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa4\x95\xe0\xa5\x8d\xe0\xa4\xb7\xe0\xa5\x8d\xe0\xa4\xa3|\\n12|\\n" क्ष्ण| 12|
Screenshot:
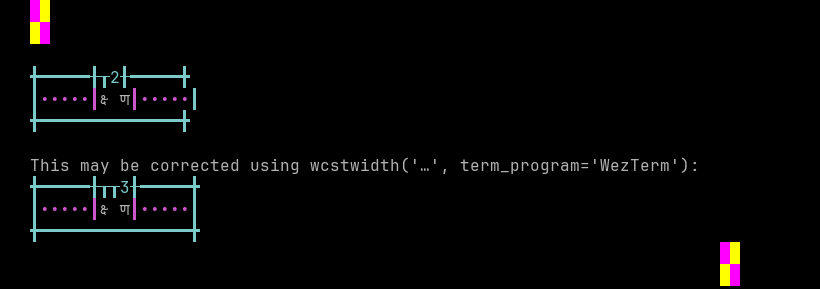
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 3.
Burmese
Sequence of language Burmese from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u1000’ |
Lo |
1 |
MYANMAR LETTER KA |
|
2 |
‘\u1031’ |
Mc |
0 |
MYANMAR VOWEL SIGN E |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe1\x80\x80\xe1\x80\xb1|\\n12|\\n" ကေ| 12|
Screenshot:
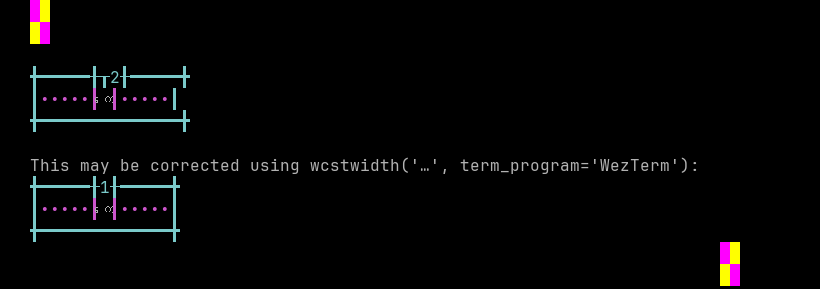
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 1.
Khmer, Central
Sequence of language Khmer, Central from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u1780’ |
Lo |
1 |
KHMER LETTER KA |
|
2 |
‘\u17b6’ |
Mc |
0 |
KHMER VOWEL SIGN AA |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe1\x9e\x80\xe1\x9e\xb6|\\n12|\\n" កា| 12|
Screenshot:
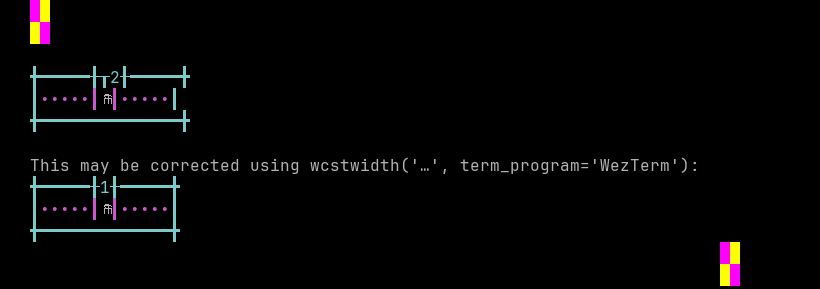
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 1.
Sanskrit
Sequence of language Sanskrit from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
|
2 |
‘\u094d’ |
Mn |
0 |
DEVANAGARI SIGN VIRAMA |
|
3 |
‘\u0924’ |
Lo |
1 |
DEVANAGARI LETTER TA |
|
4 |
‘\u094d’ |
Mn |
0 |
DEVANAGARI SIGN VIRAMA |
|
5 |
‘\u092f’ |
Lo |
1 |
DEVANAGARI LETTER YA |
|
6 |
‘\u094b’ |
Mc |
0 |
DEVANAGARI VOWEL SIGN O |
|
7 |
‘\u0903’ |
Mc |
0 |
DEVANAGARI SIGN VISARGA |
Total codepoints: 7
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa4\x95\xe0\xa5\x8d\xe0\xa4\xa4\xe0\xa5\x8d\xe0\xa4\xaf\xe0\xa5\x8b\xe0\xa4\x83|\\n12|\\n" क्त्योः| 12|
Screenshot:
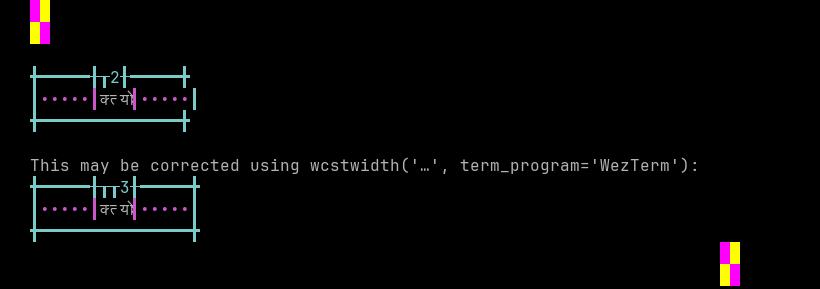
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 3.
Marathi
Sequence of language Marathi from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u091a’ |
Lo |
1 |
DEVANAGARI LETTER CA |
|
2 |
‘\u093e’ |
Mc |
0 |
DEVANAGARI VOWEL SIGN AA |
|
3 |
‘\u0902’ |
Mn |
0 |
DEVANAGARI SIGN ANUSVARA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa4\x9a\xe0\xa4\xbe\xe0\xa4\x82|\\n12|\\n" चां| 12|
Screenshot:
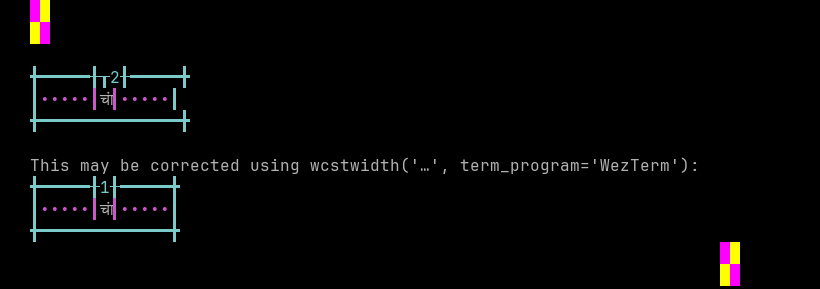
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 1.
Hindi
Sequence of language Hindi from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
|
2 |
‘\u093e’ |
Mc |
0 |
DEVANAGARI VOWEL SIGN AA |
|
3 |
‘\u0902’ |
Mn |
0 |
DEVANAGARI SIGN ANUSVARA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa4\x95\xe0\xa4\xbe\xe0\xa4\x82|\\n12|\\n" कां| 12|
Screenshot:
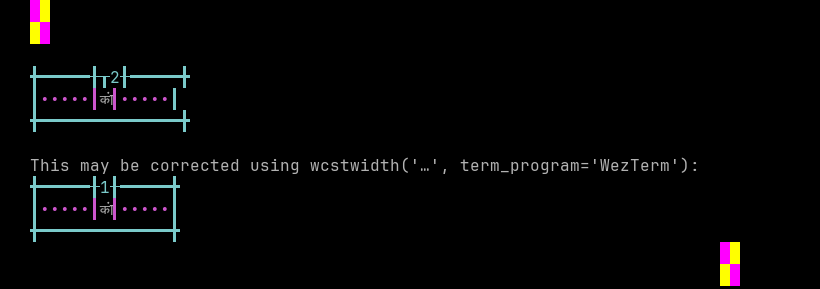
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 1.
Khün
Sequence of language Khün from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u1a20’ |
Lo |
1 |
TAI THAM LETTER HIGH KA |
|
2 |
‘\u1a6e’ |
Mc |
0 |
TAI THAM VOWEL SIGN E |
|
3 |
‘\u1a60’ |
Mn |
0 |
TAI THAM SIGN SAKOT |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe1\xa8\xa0\xe1\xa9\xae\xe1\xa9\xa0|\\n12|\\n" ᨠᩮ᩠| 12|
Screenshot:
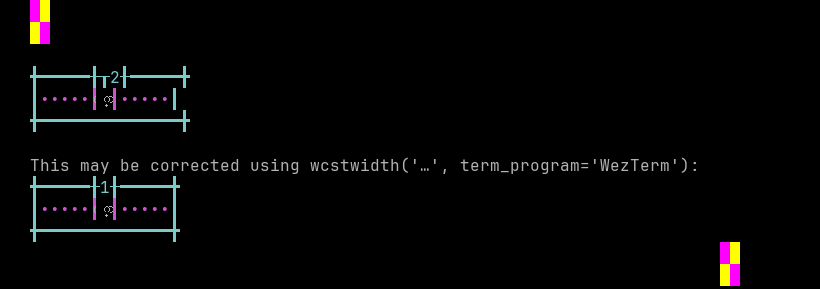
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 1.
Telugu
Sequence of language Telugu from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0c05’ |
Lo |
1 |
TELUGU LETTER A |
|
2 |
‘\u0c02’ |
Mc |
0 |
TELUGU SIGN ANUSVARA |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xb0\x85\xe0\xb0\x82|\\n12|\\n" అం| 12|
Screenshot:
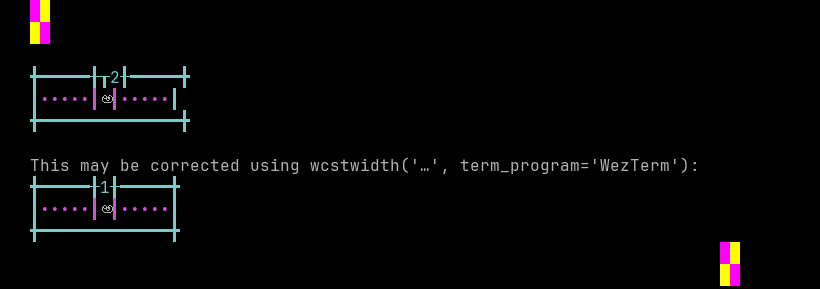
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 1.
Maithili
Sequence of language Maithili from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0915’ |
Lo |
1 |
DEVANAGARI LETTER KA |
|
2 |
‘\u093f’ |
Mc |
0 |
DEVANAGARI VOWEL SIGN I |
|
3 |
‘\u0902’ |
Mn |
0 |
DEVANAGARI SIGN ANUSVARA |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa4\x95\xe0\xa4\xbf\xe0\xa4\x82|\\n12|\\n" किं| 12|
Screenshot:
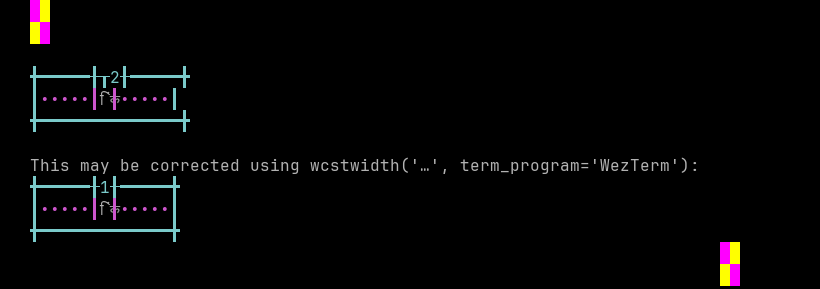
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 1.
Mon
Sequence of language Mon from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u1000’ |
Lo |
1 |
MYANMAR LETTER KA |
|
2 |
‘\u1031’ |
Mc |
0 |
MYANMAR VOWEL SIGN E |
|
3 |
‘\u102f’ |
Mn |
0 |
MYANMAR VOWEL SIGN U |
Total codepoints: 3
Shell test using printf(1),
'|'should align in output:$ printf "\xe1\x80\x80\xe1\x80\xb1\xe1\x80\xaf|\\n12|\\n" ကေု| 12|
Screenshot:
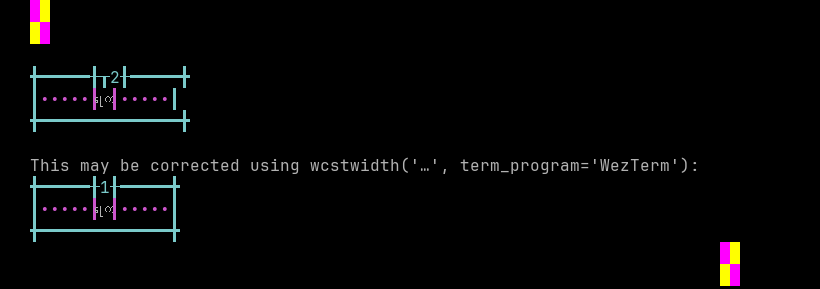
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 1.
Javanese (Javanese)
Sequence of language Javanese (Javanese) from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\ua98f’ |
Lo |
1 |
JAVANESE LETTER KA |
|
2 |
‘\ua983’ |
Mc |
0 |
JAVANESE SIGN WIGNYAN |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xea\xa6\x8f\xea\xa6\x83|\\n12|\\n" ꦏꦃ| 12|
Screenshot:
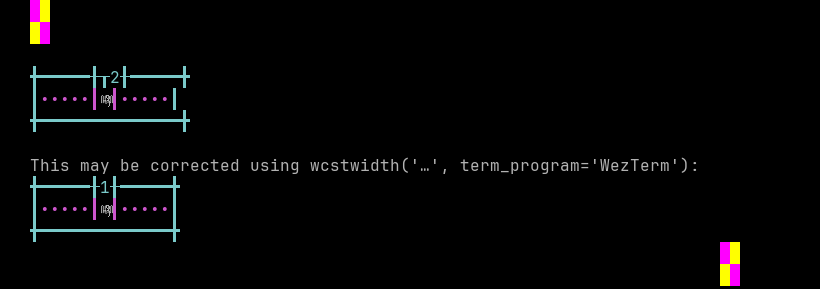
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 1.
Nepali
Sequence of language Nepali from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u091a’ |
Lo |
1 |
DEVANAGARI LETTER CA |
|
2 |
‘\u094b’ |
Mc |
0 |
DEVANAGARI VOWEL SIGN O |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe0\xa4\x9a\xe0\xa5\x8b|\\n12|\\n" चो| 12|
Screenshot:
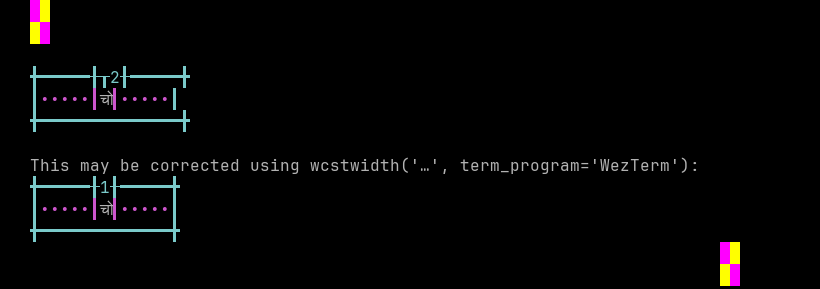
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 1.
Chakma
Sequence of language Chakma from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\U00011103’ |
Lo |
1 |
CHAKMA LETTER AA |
|
2 |
‘\U0001112c’ |
Mc |
0 |
CHAKMA VOWEL SIGN E |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xf0\x91\x84\x83\xf0\x91\x84\xac|\\n12|\\n" 𑄃𑄬| 12|
Screenshot:
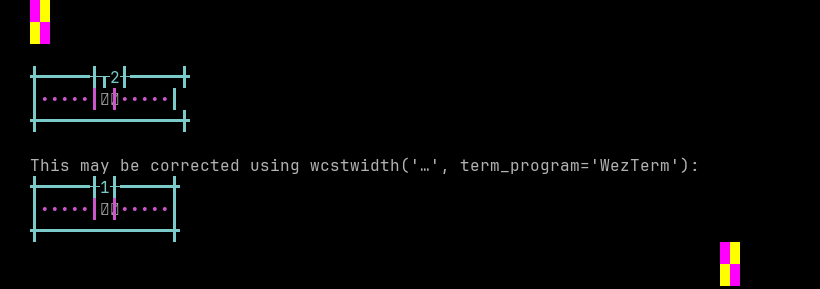
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 1.
Shan
Sequence of language Shan from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u1004’ |
Lo |
1 |
MYANMAR LETTER NGA |
|
2 |
‘\u1084’ |
Mc |
0 |
MYANMAR VOWEL SIGN SHAN E |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xe1\x80\x84\xe1\x82\x84|\\n12|\\n" ငႄ| 12|
Screenshot:
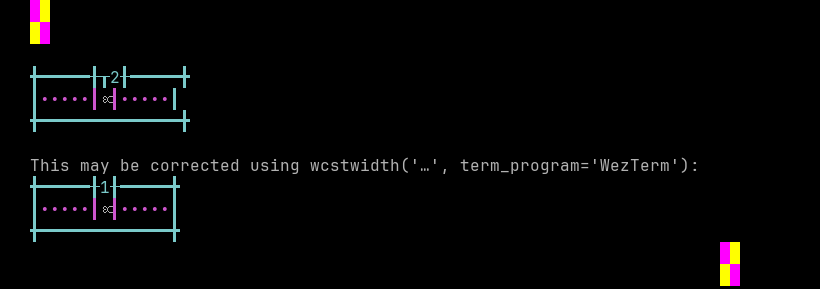
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 1.
Urdu
Sequence of language Urdu from midpoint of alignment failure records:
# |
Codepoint |
Python |
Category |
wcwidth |
Name |
|---|---|---|---|---|---|
1 |
‘\u0601’ |
Cf |
1 |
ARABIC SIGN SANAH |
|
2 |
‘\u06f1’ |
Nd |
1 |
EXTENDED ARABIC-INDIC DIGIT ONE |
Total codepoints: 2
Shell test using printf(1),
'|'should align in output:$ printf "\xd8\x81\xdb\xb1|\\n12|\\n" ۱| 12|
Screenshot:
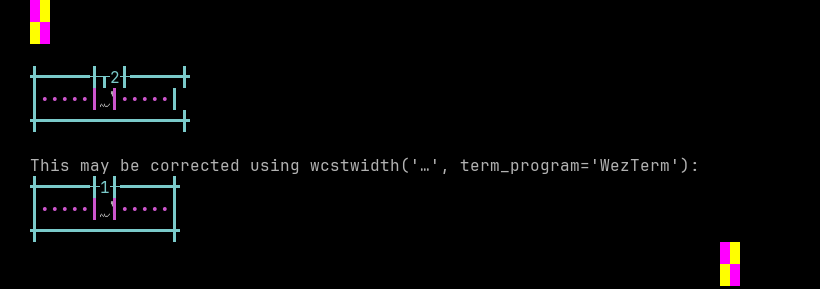
python wcwidth.wcswidth() measures width 2, while WezTerm measures width 1.
DEC Private Modes Support
DEC private modes results for WezTerm: 4 changeable modes of 5 supported out of 8 total modes tested (62.5% support, 50.0% changeable).
Complete list of DEC private modes tested:
Mode |
Name |
Description |
Supported |
Changeable |
Enabled |
|---|---|---|---|---|---|
1004 |
FOCUS_IN_OUT_EVENTS |
Send FocusIn/FocusOut events |
Yes |
Yes |
No |
1006 |
MOUSE_EXTENDED_SGR |
Enable SGR Mouse Mode |
Yes |
Yes |
No |
2004 |
BRACKETED_PASTE |
Set bracketed paste mode |
Yes |
Yes |
No |
2026 |
SYNCHRONIZED_OUTPUT |
Synchronized Output |
Yes |
Yes |
No |
2027 |
GRAPHEME_CLUSTERING |
Grapheme Clustering |
Yes |
No |
Yes |
2031 |
COLOR_PALETTE_UPDATES |
Color palette updates |
No |
No |
No |
2048 |
IN_BAND_WINDOW_RESIZE |
In-Band Window Resize Notifications |
No |
No |
No |
5522 |
BRACKETED_PASTE_MIME |
Bracketed Paste MIME |
No |
No |
No |
Summary: 4 changeable, 4 not changeable.
Kitty Keyboard Protocol
WezTerm does not support the Kitty keyboard protocol.
XTGETTCAP (Terminfo Capabilities)
WezTerm supports the XTGETTCAP sequence and reports 136 terminfo capabilities (Full).
# |
Capability |
Description |
Value |
|---|---|---|---|
1 |
Cr |
Set cursor color |
|
2 |
Cs |
Reset cursor color |
|
3 |
Ms |
Clipboard set |
|
4 |
RGB |
Bits per color channel (8 = 24-bit truecolor) |
|
5 |
Se |
Reset underline style |
|
6 |
Setulc |
Set underline color |
|
7 |
Smol |
Set overline mode |
|
8 |
Smulx |
Styled underline |
|
9 |
Ss |
Set underline style |
|
10 |
Sync |
Synchronized output |
|
11 |
TN |
Terminal name |
|
12 |
Tc |
Truecolor (24-bit RGB) |
|
13 |
XM |
Enter marks mode (kitty) |
|
14 |
acsc |
Alternate character set |
|
15 |
am |
Auto right margin |
|
16 |
bce |
Background color erase |
|
17 |
bel |
Bell |
|
18 |
blink |
Enter blink mode |
|
19 |
bold |
Enter bold mode |
|
20 |
ccc |
Can redefine colors |
|
21 |
civis |
Hide cursor |
|
22 |
clear |
Clear screen |
|
23 |
cnorm |
Normal cursor |
|
24 |
colors |
Max colors on screen |
|
25 |
cols |
Columns |
|
26 |
cr |
Carriage return |
|
27 |
csr |
Change scroll region |
|
28 |
cub |
Cursor left n |
|
29 |
cub1 |
Cursor left |
|
30 |
cud |
Cursor down n |
|
31 |
cud1 |
Cursor down |
|
32 |
cuf |
Cursor right n |
|
33 |
cuf1 |
Cursor right |
|
34 |
cup |
Cursor address |
|
35 |
cuu |
Cursor up n |
|
36 |
cuu1 |
Cursor up |
|
37 |
cvvis |
Very visible cursor |
|
38 |
dch |
Delete n characters |
|
39 |
dch1 |
Delete character |
|
40 |
dim |
Enter dim mode |
|
41 |
dl |
Delete n lines |
|
42 |
dl1 |
Delete line |
|
43 |
dsl |
Disable status line |
|
44 |
ech |
Erase characters |
|
45 |
ed |
Clear to end of screen |
|
46 |
el |
Clear to end of line |
|
47 |
el1 |
Clear to start of line |
|
48 |
flash |
Flash screen |
|
49 |
fsl |
From status line |
|
50 |
home |
Cursor home |
|
51 |
hpa |
Horizontal position |
|
52 |
hs |
Has status line |
|
53 |
ht |
Horizontal tab |
|
54 |
hts |
Set tab stop |
|
55 |
ich |
Insert n characters |
|
56 |
il |
Insert n lines |
|
57 |
il1 |
Insert line |
|
58 |
ind |
Scroll forward |
|
59 |
indn |
Scroll forward n |
|
60 |
initc |
Initialize color |
|
61 |
invis |
Invisible cursor |
|
62 |
is2 |
Init 2 string |
|
63 |
it |
Init tabs |
|
64 |
kDC |
Shifted delete-char key |
|
65 |
kEND |
Shifted end key |
|
66 |
kHOM |
Shifted home key |
|
67 |
kIC |
Shifted insert-char key |
|
68 |
kLFT |
Shifted left-arrow key |
|
69 |
kNXT |
Shifted next-page key |
|
70 |
kPRV |
Shifted previous-page key |
|
71 |
kRIT |
Shifted right-arrow key |
|
72 |
kb2 |
Keypad center |
|
73 |
kbs |
Backspace key |
|
74 |
kcbt |
Back-tab key |
|
75 |
kcub1 |
Left arrow key |
|
76 |
kcud1 |
Down arrow key |
|
77 |
kcuf1 |
Right arrow key |
|
78 |
kcuu1 |
Up arrow key |
|
79 |
kdch1 |
Delete character key |
|
80 |
kend |
End key |
|
81 |
kent |
Enter/send key |
|
82 |
kf1 |
Function key F1 |
|
83 |
khome |
Home key |
|
84 |
kich1 |
Insert character key |
|
85 |
kind |
Scroll-down key |
|
86 |
km |
Has meta key |
|
87 |
kmous |
Mouse key |
|
88 |
knp |
Next page key |
|
89 |
kpp |
Previous page key |
|
90 |
kri |
Scroll-up key |
|
91 |
lines |
Lines |
|
92 |
mc5i |
Will not echo input |
|
93 |
mir |
Move in insert mode |
|
94 |
msgr |
Move in standout mode |
|
95 |
npc |
No pad character |
|
96 |
oc |
Original colors |
|
97 |
op |
Original pair |
|
98 |
pairs |
Max color pairs |
|
99 |
rc |
Restore cursor |
|
100 |
rep |
Repeat character |
|
101 |
rev |
Enter reverse mode |
|
102 |
ri |
Reverse index |
|
103 |
rin |
Scroll reverse n |
|
104 |
ritm |
Exit italics mode |
|
105 |
rmacs |
Exit alternate charset mode |
|
106 |
rmam |
Disable line wrap |
|
107 |
rmcup |
Exit alt screen |
|
108 |
rmir |
Exit insert mode |
|
109 |
rmkx |
Keypad local mode |
|
110 |
rmm |
Reset meta mode |
|
111 |
rmso |
Exit standout mode |
|
112 |
rmul |
Exit underline mode |
|
113 |
rs1 |
Reset string 1 |
|
114 |
rs2 |
Reset string 2 |
|
115 |
sc |
Save cursor |
|
116 |
setab |
Set background color |
|
117 |
setaf |
Set foreground color |
|
118 |
sgr |
Set attributes |
|
119 |
sgr0 |
Reset attributes |
|
120 |
sitm |
Enter italics mode |
|
121 |
smacs |
Enter alternate charset mode |
|
122 |
smam |
Enable line wrap |
|
123 |
smcup |
Enter alt screen |
|
124 |
smir |
Enter insert mode |
|
125 |
smkx |
Keypad transmit mode |
|
126 |
smso |
Enter standout mode |
|
127 |
smul |
Enter underline mode |
|
128 |
tbc |
Clear all tabs |
|
129 |
tsl |
To status line |
|
130 |
u6 |
CPR response format |
|
131 |
u7 |
CPR request |
|
132 |
u8 |
DA response format |
|
133 |
u9 |
DA request |
|
134 |
vpa |
Vertical position |
|
135 |
xenl |
Newline glitch |
|
136 |
xm |
Exit marks mode (kitty) |
|
The XTGETTCAP sequence (DCS + q Pt ST) allows applications to query
terminfo capabilities directly from the terminal emulator, rather than relying
on the system terminfo database.
Text Sizing Protocol (OSC 66)
WezTerm does not support the Text Sizing protocol.
Truecolor Support
WezTerm supports 24-bit truecolor, detectable via:
XTGETTCAP (RGB capability): yes (RGB)
DECRQSS (truecolor probe): no
COLORTERM: yes (truecolor)
OSC 52 Clipboard Support
WezTerm supports OSC 52 clipboard operations (detected via XTGETTCAP Ms).
DA1 extension 52: no
XTGETTCAP Ms: yes
Terminal Identification
WezTerm is identified as WezTerm version 20240203-110809-5046fc22 (detected via XTVERSION + XTGETTCAP TN).
XTVERSION (raw): WezTerm 20240203-110809-5046fc22
XTVERSION: yes
XTGETTCAP TN: yes (WezTerm)
ENQ: no
TERM_PROGRAM: yes (WezTerm)
TERM: no (xterm-256color)
Reproduction
To reproduce these results for WezTerm, install and run ucs-detect with the following commands:
uvx ucs-detect --rerun data/wezterm.yaml
Test Performance
The test suite completed in 92.16 seconds (92s).
Mean CPU: 97.6%
Mean RSS: 178.5 MB
Total time: 92.2s
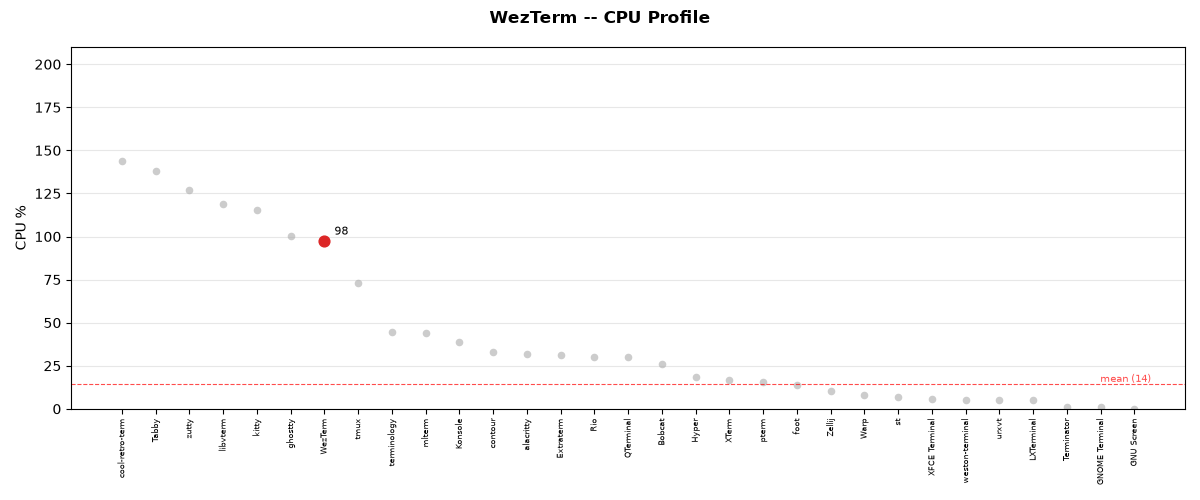
CPU usage during test execution for WezTerm.
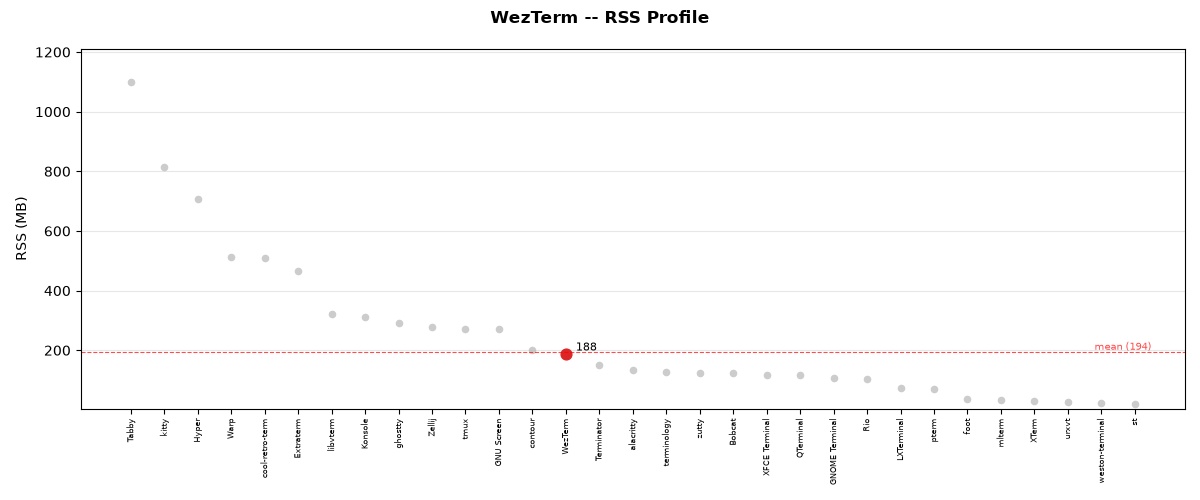
RSS memory usage during test execution for WezTerm.
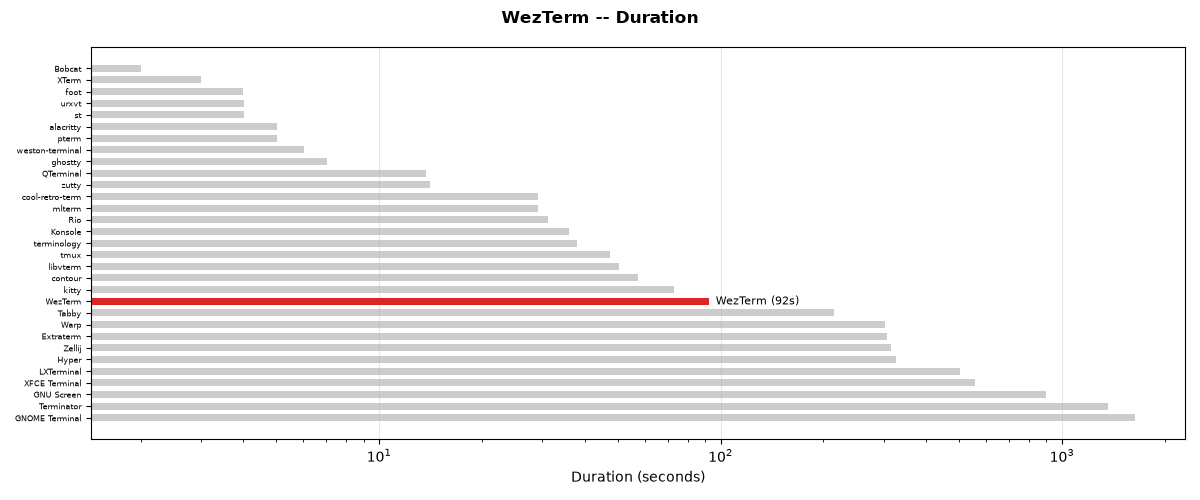
Test duration for WezTerm compared to all other terminals.
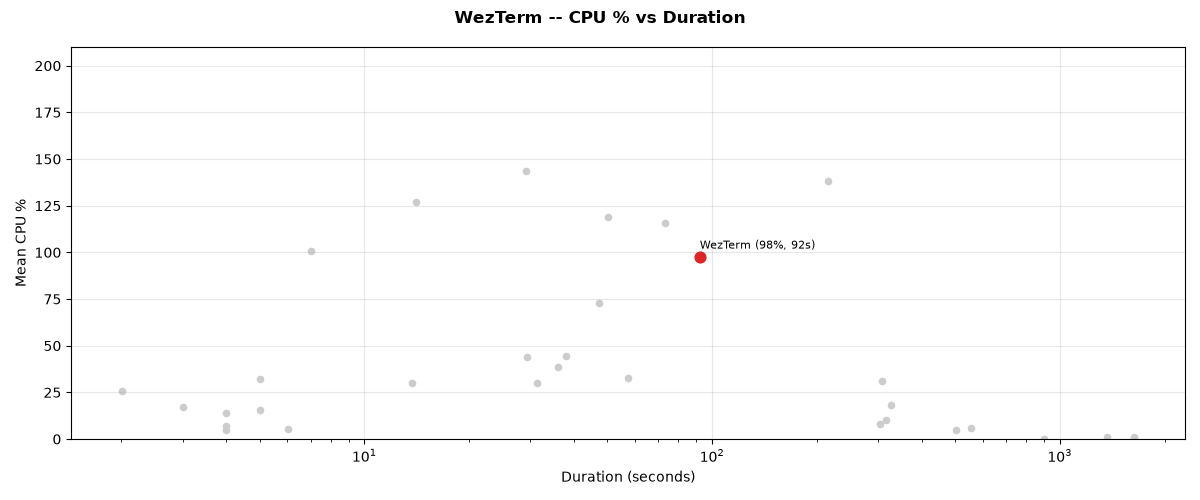
CPU % vs duration trade-off for WezTerm.